旗舰遇阻 Sonnet 5升级救急 性能媲美Opus
六月尾声,Anthropic 在官方网站发布了两则消息。
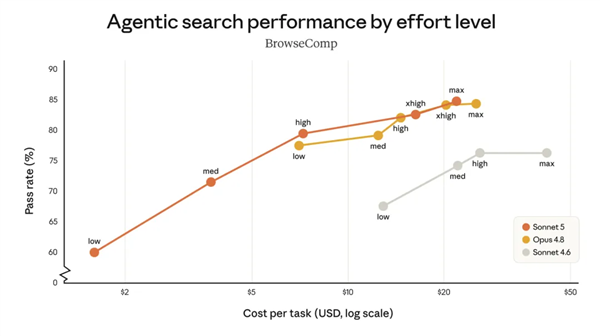
不同模型不同层级下的代理任务完成情况 Sonnet 5 与 Opus4.8 相差无几|图片来源:Anthropic
1 代理功能强化,Sonnet 5 逼近 Opus
先看 Sonnet 5 的数据。
在 SWE-bench Verified 这个评估编码能力的基准测试中,Sonnet 5 获得了 92.4% 的成绩。Anthropic 自家的 Opus 4.6 是 80.8%,OpenAI 的 GPT-5.4 为 57.7%。这是 Anthropic 的中端模型,以 Sonnet 的价格,却达到了超越旗舰的水平。
价格方面,发布初期每百万输入 token 收费 2 美元,输出 10 美元,8 月 31 日后调整为 3 美元和 15 美元。相比 Opus 4.8,便宜了许多,也比 GPT-5.5 和 Gemini 3.1 Pro 更低。
Anthropic 在发布说明中提及,Sonnet 5 能够规划任务、使用浏览器和终端工具,以「自主模式」运作——而「这在数月前还需依赖更大、更昂贵的模型」。这番表述十分坦诚,相当于公开承认:旗舰模型的能力正迅速下放,速度超出外界预想。
Zapier 的工程师 Daniel Shepard 测试了一项两步任务,让模型同时更新 Salesforce 账户等级并向企业联系人发送通知。他的感受是,Sonnet 5「从头到尾完成了整个任务,这在以前会中途卡住」。这类具体的工程反馈比基准分数更具参考意义——它表明代理任务的可靠性门槛正在被跨越,而且是在中端价位上实现的。
对于构建多步骤自动化流程的团队而言,这改变了关键的成本核算:以往必须调用旗舰模型才能完成的任务,如今可以用三分之一甚至更低的成本搞定。
02 政府的信函,与被抑制的旗舰
将时间回溯两周,此次发布的背景会更明朗。
6 月 12 日,Anthropic 暂停了 Fable 5 和 Mythos 5 两个新模型的访问权限,原因是美国政府的出口管制指令——禁止非美国国民使用这两个模型。外界推测触发点之一是政府发现了 Fable 5 的某种破解方法,能绕过其最强能力的安全防护。
两周后,6 月 26 日,美国商务部长发出一封信,批准 Anthropic 向约 100 家公司和联邦机构有限发布 Mythos 5,表述为「已确认存在适当的保护措施」。但 Fable 5 的访问权限至今未获批准恢复。
因此,6 月 30 日当天,Anthropic 的实际处境是:最强的两个模型一个受限、一个仍被冻结,商业发布受制于政府窗口。在此背景下推出 Sonnet 5,并着重强调其代理能力「接近 Opus 4.8」,逻辑变得通顺了——被压制的旗舰系列无法正常铺展,那就让中端产品支撑当前的商业需求。
这不是 Anthropic 首次在监管与商业节奏之间进行周旋。今年 6 月它还在首尔开设了新办事处,持续推进在韩国市场的本地化合作。一边是旗舰被美国政府束缚,一边是国际市场仍在推进,两条线并行,内部的协调压力可想而知。
03 Claude 的 AI4S
Claude Science 是今天另一条更低调但可能更持久的线索。
它的形态是「AI 工作台」,整合了 60 多个科学数据库和专用工具包,核心不是新模型,而是一套工作流。底层调用的仍是 Opus 4.8 这类现有模型,但外围包裹了一层专门为科研设计的环境——生成可审计的产出、灵活的计算资源接入,以及一个 Anthropic 特别强调的功能:
可复现性。
每张图表都附有生成它的完整代码、运行环境、纯语言说明,以及完整的消息历史。研究人员数月后仍可追溯任何结果的源头。在学术界,可复现性危机已争论十几年,AI 工具若能系统性地将此痛点融入工作流,对科研群体的吸引力不会小。
Anthropic 宣布将支持最多 50 个 Claude Science 科研项目,每个项目提供最多 3 万美元的计算积分,合作方 Modal 另提供最多 2000 美元的计算资源。这个规模不算大,更像是为了锁定早期用户群体、跑通模式。
今年 4 月,OpenAI 发布了 GPT-Rosalind,一个针对生物推理微调的专用模型,当时以研究预览形式推出,访问权限限于美国境内的合格企业客户。
两家的策略分叉明显——OpenAI 选择了定制模型,Anthropic 选择了工作流整合。哪条路更适合科研场景,目前尚难判断,但 Anthropic 的逻辑有一定说服力:大多数科学家并不缺更聪明的模型,他们缺的是一个能将数据库、工具、代码环境和结果审计串联起来的稳定工作台。(或者说,他们缺的是不用每次打开五个窗口互相复制粘贴的工作流——这大概是当今科研圈最普遍的日常。)
04 从模型竞赛到系统竞争
整个 AI 行业在过去一年里经历了一次微妙的叙事转移。
2024 年之前,模型发布基本等同于「性能排行榜」的一个新条目,讨论焦点是参数量、基准分数、上下文窗口。而今,头部公司发布新模型时越来越多地谈论「总体拥有成本」「工作流集成」「代理任务的可靠性」,基准测试退居配角位置。
Sonnet 5 和 Claude Science 是这一趋势的缩影。前者的核心价值不是「更聪明」,而是「以更低成本做到足够聪明」;后者的核心价值不是「新模型」,而是「将模型接入你原本的工作环境」。
业内一种观点正成为共识:性能竞赛对大多数实际应用场景而言已走到一个拐点,绝大多数企业用户所需的能力,现有中端模型基本都够用,剩下的差异化要靠成本、可靠性和生态集成来决定。
Anthropic 今日的两个发布,一个向左,一个向右,一个对准开发者和企业的代理场景,一个对准科学家的专业工作流,看起来像是在同时押注两个方向。但更准确的理解或许是:它在试探,当模型本身不再是主要壁垒时,什么才是留住用户的真正理由。
Fable 5 的访问权限尚未恢复,下一步如何走还要等政府那边的窗口。但在等待窗口开启之前,中端产品线和垂直工具的版图已先铺开了。