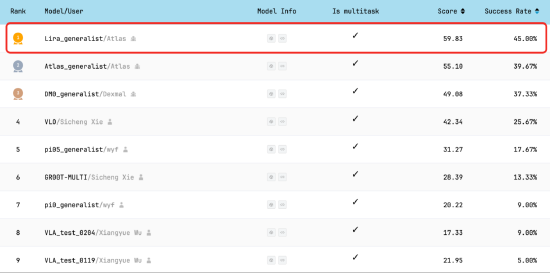
重磅推出!阿里Qwen-Robot系列具身大模型问世
新浪科技讯 6月16日下午消息,阿里巴巴发布千问具身智能大模型Qwen-Robot系列,包含VLA操作模型Qwen-RobotManip、VLN移动模型Qwen-RobotNav 和世界模型 Qwen-RobotWorld三大模型。这三个模型分别为机器人(17.260, -0.70, -3.90%)装上灵巧的手、认路的脚和会思考的大脑,既可单独部署,也能协同运转。
VLA (Vision-Language-Action,视觉-语言-动作)模型是当前具身智能最核心基础模型之一,它将视觉感知、语言理解和动作决策融合,让机器人看得懂、能动手。传统VLA模型的核心痛点是迁移能力不足,换机器人、换场景性能就下降。让不同形态的机器人能听懂一个模型指挥,需要解决动作统一和空间统一两个核心问题,Qwen-RobotManip正是从这两点切入。据悉,Qwen-RobotManip用一套80维的统一动作表征,为不同硬件定义了通用的“-{肢体语言}-,让机器人习得基础物理规律与动作逻辑,动作不再是生硬模仿。搭载在不同的硬件中,Qwen-RobotManip只需数步反馈即可自动适配,性能稳定高效。
如果说 VLA 模型让机器人能动手,那么VLN(Vision-Language Navigation,视觉语言导航)模型,就是让机器人能认路、会跑腿。Qwen-RobotNav 基于 Qwen-VL 构建,将语言指令导航、目标搜索、自动驾驶等五大任务族统一到同一个框架,遇到复杂任务无需人工切换模型。
Qwen-RobotWorld则基于对物理规律的理解,可推理和模拟出下一个时间点机器人的合理动作和状态,让机器人在现实世界中可按图索骥般地行动。(文猛)
责任编辑:张文
新浪财经声明:此消息系转载自合作媒体,新浪财经登载此文出于传递更多信息之目的,文章内容仅供参考,不构成投资建议。
郑重声明:1.根据《证券法》规定,禁止编造、传播虚假信息或者误导性信息,扰乱证券市场;2.用户在本社区发表的所有资料、言论等仅代表个人观点,与本网站立场无关,不对您构成任何投资建议。用户应基于自己的独立判断,自行决定证券投资并承担相应风险。