梁文锋力作DSpark:掌握这十大核心即可通关
出处:量子位
梁文锋挂名的DeepSeek最新论文DSpark或许你已看过——
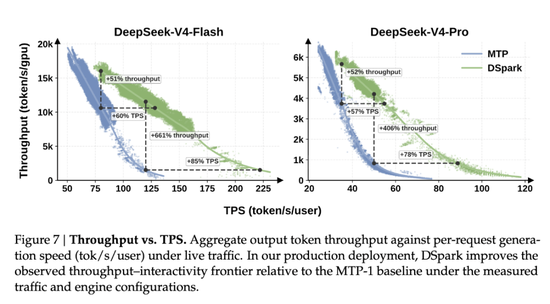
单用户速率拔高85%、高并发环境下有效吞吐暴增4倍。
然而你确实领悟了吗?
莫慌,已有行家帮你剖析完毕。
Fireworks AI的联合创始人兼CTO、PyTorch核心开发者Dmytro Dzhulgakov把全篇论文归纳成10大要点,从最底层的GPU显存访问特征聊到最顶层的在线自适应调度。
他指出:
DeepSeek此番架构的真正核心在于系统工程与模型协同设计。
相关基础理念前人虽已提出,难能可贵的是其将多种技术整合为一套自适应完整系统,达成了端到端的显著性能跃升。
接下来咱们顺着这10大要点梳理一遍DSpark。
10大要点读懂DSpark
批处理解码(Batching in LLM Decoding)
若想弄懂大模型各类推理加速窍门,首当其冲要明白GPU一个极为特殊的运行规律:
让GPU同时解码10个token,其实只比解码1个token慢一丁点。
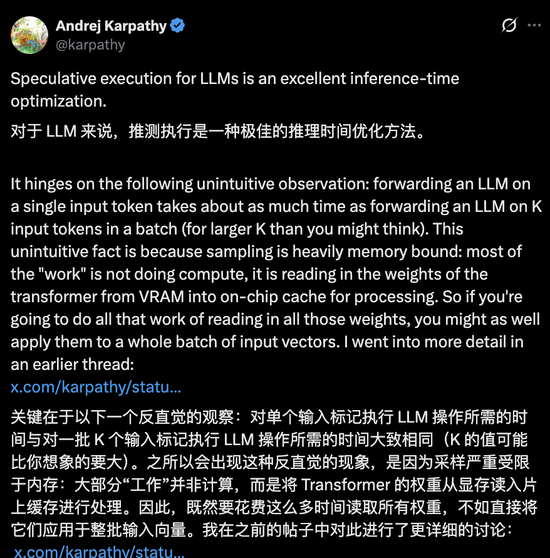
卡帕西曾指出,根源在于大模型推理的瓶颈并非浮点运算,而是显存带宽,GPU绝大部分时间耗费在把模型权重从显存转移到计算核心上。
搬一回也是搬,搬十回也是搬,既然权重已加载入缓存,不如一次搬运、做十件事。
这便是连续批处理:把多个请求的token塞入同一批次,让每次显存读取都发挥最大效用。
明白这点,就知晓为何推测解码能生效,其本质就是把“猜出的多个候选token”打包成一个批次交给大模型检验,而检验批次的代价,远低于逐个生成的代价。
推测解码(Speculative Decoding)
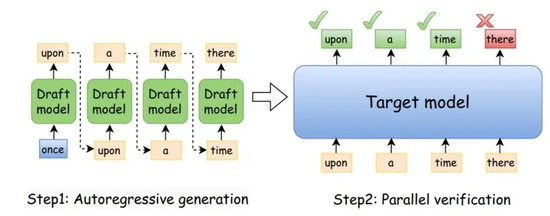
大模型生成属于自回归模式,第N+1个token依赖第N个token的输出,无法直接并行。
但存在一种变通之法,若能‘猜’出后续若干token,即可把猜出的候选序列一次性喂给大模型做批量检验。
检验借助拒绝采样,系统逐一核查候选token,采纳最长的正确前缀,在首个分歧处重新采样一个token。
此规则在数学上确保输出分布与原模型完全相符,毫无质量折损。
故而推测解码的本质是用“猜+验”取代“逐字生成”。
猜的环节用小模型能极快,验的环节展开批量检验能极高效,所以最终每一步皆可往前跃进多个token。
DSpark正是此方向上的最新突破。
草稿模型(Draft Model)
那如何猜呢?
最直白的方案是用一个小模型充当“草稿器”。
例如用Qwen 0.8B为Qwen 397B开路,小模型运行快,把候选序列备好,大模型仅需做一次前向传播来检验。
通过则全盘接纳,未通过则从分歧处重来。
此设计把推理流程拆分为两个角色,速度型草稿器负责猜,力量型目标模型负责判。
两者默契配合,整体速率就能大幅跃升。
但欲达默契配合,背后需平衡海量工程取舍,随后的几个要点便在阐述这些取舍。
推测并非免费(Speculation is Not Free)
草稿模型带来了额外开销。
若草稿器自身运行过慢,或一次猜了16个token但仅前3个被采纳,那这笔账便亏本了。
论文给出了一个核心公式来描绘实际延迟:
每个token的耗时= (草稿耗时+检验耗时) /被采纳的token数τ。
基于此理论,加速唯有三条路径,削减草稿耗时(猜得更快)、拔高τ(猜得更准)、降低检验浪费(验得更精明)。
猜得多未必佳,因多猜的token若大概率遭拒,它们只会徒然占用检验批次的宝贵算力。
所以DSpark的整篇论文,可视为同步撬动这三个杠杆的系统性探索。
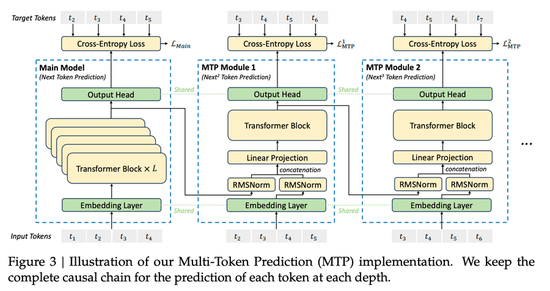
Eagle与MTP,复用目标模型的内在认知
第一根杠杆,即优化草稿模型自身的架构。
草稿模型无需从零训练一个完整小模型,有一种更明智的招数是直接将目标模型最后一层的隐藏状态取来,在其上添加1–2层Transformer头充当草稿器。
此乃Eagle系列与MTP(Multi-Token Prediction)的逻辑。
△图源:DeepSeek-V3 Technical Report
益处有二,一是快,草稿器仅1–2层,运算量极低;
二是准,因其直接吸收目标模型的内在认知,即最后一层激活值,等同于站在巨人肩上猜下一步,比从头用小模型独立推理靠谱得多。
DeepSeek-V3早已在用MTP做单token推测(MTP-1)。
DSpark论文内所有的加速数据皆与MTP-1此基线对照,换言之,60%–85%的速率提升是在已优化基底上再度叠加的。
DFlash,借并行一口气猜完
然Eagle/MTP的缺陷在于,欲生成N个候选token,需运行N步,第2个token依赖第1个的输出,第3个依赖第2个……串行链条无法斩断。
DFlash的逻辑是参考扩散模型之道,一次前向传播便将全部N个候选位置同步生成。
速率固然快,但代价是各位置间缺乏依赖。开篇几个token或许极准,因上下文信息充沛,但越靠后越糟糕。
论文将此问题称作多模态碰撞。
举例而言,位置1采样出“of”,位置2独立采样出“problem”,各自视概率皆合理,拼在一块却成了“of problem”这般不通顺的搭配。
位置越靠后,此等跑偏几率越高,接受率急剧跌落。
这便是所谓的后缀衰减,亦是纯并行方案于实际部署中加速成效打折的根源。
DSpark≈Eagle+DFlash,鱼与熊掌兼得
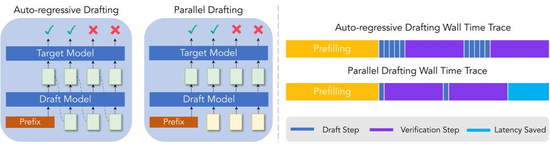
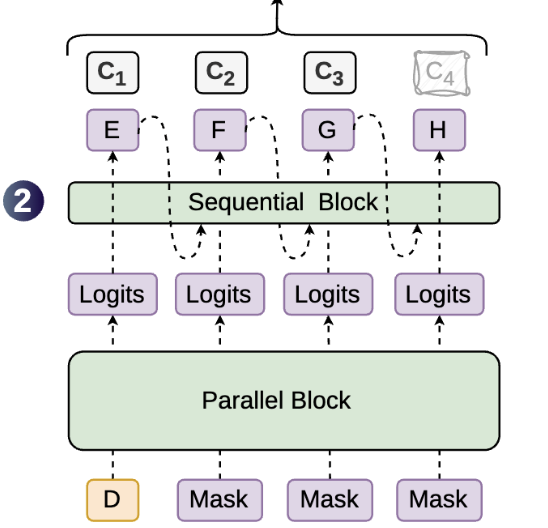
DSpark的核心创新,一言以蔽之即把并行与串行组合,各取其长。
具体操作分两步。第一步,用DFlash的并行骨干网络一口气生成所有位置的基础logits,此步保障速率。
第二步,用一个轻量级的顺序头从前向后逐个位置注入前缀依赖偏置,此步负责修补后缀衰减。
用上述案例审视,成效是:
位置1采样出“of”后,顺序头会把位置2的概率分布朝“course”方位推,同时压低“problem”的概率。
并行骨干确保了整体速率不拖累,顺序头确保了后半段接受率不崩塌。
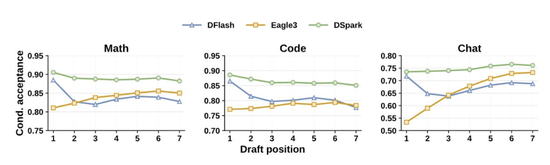
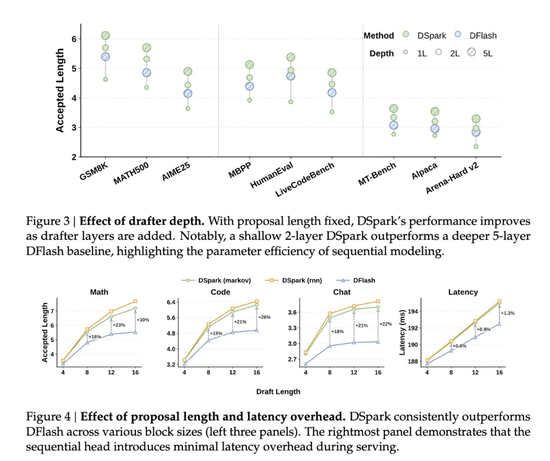
在论文的离线测试里,DSpark的平均接受长度比Eagle3高出26%–31%,比DFlash高出16%–18%。
两层DSpark甚至胜过五层DFlash。
更实惠的串行模块,马尔可夫头
既然第二步需添一个顺序头,那其开销岂非将第一步省下的时间又吞回去了?
DSpark的答案是:不会,因并行骨干已把上下文信息编码妥当,串行步骤无需再做完整的注意力计算,仅需做极轻量的修正。
默认方案是一个马尔可夫头,它仅看前一个token便判定当前位置的修正方向,借由低秩分解(rank 256),即便词表达十几万token,运算开销亦几可忽略。
实测数据极具说服力,草稿长度从4扩至16,每轮额外增添的延迟仅有0.2%–1.3%,但接受长度最多拔高了30%。
论文内还提供了一款 RNN 头的可选方案,可追踪整个草稿块的前缀信息,然实际增益有限,故默认未启用。
此亦彰显DSpark的工程审美,并非越繁杂越佳,而是寻得成本与收益的最优折中。
可变长度草稿与硬件感知调度
那每次该猜几个token呢?此问题无标准答案。
首先,不同类别的请求天然有别。
代码生成的可预测性高(语法模式强),草稿器猜8–16个token或许皆能过关;开放式闲聊不确定性大,猜4个便可能翻车。
其次,服务器的实时负载亦在波动。
GPU空闲时,多猜几个token无额外开销,反正算力闲着亦闲着;高并发时,每一块检验批次的算力皆极珍贵,不该虚耗于大概率遭拒的尾部token上。
于是DSpark用一个置信度头给每个草稿位置打分,预估其在检验中存活的概率。
此套方案会预先测定GPU在各批次规模下的硬件吞吐数据,生成吞吐量参考曲线,再依曲线结果为每条请求动态匹配最优验证长度。
整套调度逻辑全然于GPU内部执行,无需CPU介入,虽实现门槛极高,但该方案已成功落地。
在线草稿器校准
接下来,便是最后一块拼图,在线草稿置信度校准。
置信度头的理念极佳,但存在一个现实困境即“神经网络天生过度自信”。
它觉着自己猜的每个token皆对,这便致使原始置信度评分失准,该停时不停,该放手时死撑。
若直接用模型输出的概率设阈值,系统表现将跑偏。
DSpark 的举措是在运行时持续监测草稿器的实际表现。
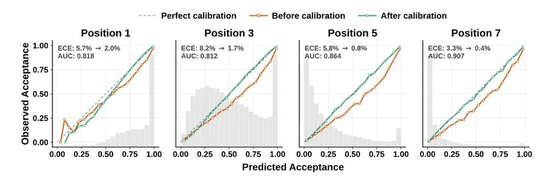
论文中运用顺序温度缩放做后处理校准,把预期校准误差从3%–8%压至约1%。
更关键的是,此校准过程属在线模式,系统边跑边调,依凭当前工作负载的实际接受率动态修正阈值。
代码任务跑多了,它便学会对代码草稿更宽容;聊天任务降临,它自动收紧阈值。
越跑越准,真正达成了自适应。
这10个要点单独看,多数确非全新,但整套方案实现了算法、调度、硬件适配三位一体的端到端工程闭环。
且DeepSpec全栈训练库同步开源,Eagle3、DFlash、DSpark三种草稿模型的训练代码悉数放出,支持Qwen3和Gemma等外部模型——
你想给自家模型训一个草稿器,直接拿去改即可。
OMT
DSpark配套的DeepSpec库现于GitHub已斩获1.4k Star,各路开发者皆开始实操内卷。
海外大佬阅毕论文火速掏出两块RTX PRO 6000在家折腾DSpark。
两块显卡火力拉满
责任编辑:郭栩彤
新浪财经声明:此消息系转载自合作媒体,新浪财经登载此文出于传递更多信息之目的,文章内容仅供参考,不构成投资建议。
郑重声明:1.根据《证券法》规定,禁止编造、传播虚假信息或者误导性信息,扰乱证券市场;2.用户在本社区发表的所有资料、言论等仅代表个人观点,与本网站立场无关,不对您构成任何投资建议。用户应基于自己的独立判断,自行决定证券投资并承担相应风险。