谷歌新算法引爆市场 内存芯片需求或迎重估?
来源:财联社
财联社3月26日讯(编辑 刘蕊)美东时间周二,谷歌推出了一项震动硅谷科技圈的全新算法:超高效AI内存压缩技术TurboQuant。
谷歌表示,这项算法能够在不牺牲准确率的情况下,将大语言模型运行时的缓存内存占用压缩至少6倍,同时带来8倍性能提升。从本质上看,它意味着人工智能可以在更少内存消耗下保留更多上下文信息。
该算法一经亮相,美股芯片板块随即承压下行。与此同时,谷歌与华尔街围绕一个核心问题展开激烈讨论:长期困扰科技巨头的内存芯片短缺局面,是否有望因此得到缓解?
TurboQuant是什么?
先来看看TurboQuant这项算法究竟是什么。
按照谷歌官网的介绍,TurboQuant是一种压缩方案,能够在完全不损失精度的情况下显著缩小模型体积,因此尤其适用于键值缓存(KV Cache)压缩以及向量检索。它主要通过两个关键环节实现这一目标:
1、高质量压缩(PolarQuant method):TurboQuant首先会对数据向量进行随机旋转。这一步巧妙地简化了数据的几何特征,使标准的高质量量化器可以分别应用到向量的不同部分。第一阶段会使用绝大多数压缩能力(大部分比特),以尽量保留原始向量中的核心概念与关键特征。
2、消除隐藏误差:TurboQuant再利用少量剩余的压缩能力(仅1比特),将QJL算法用于修正第一阶段遗留下来的微小误差。QJL阶段就像数学意义上的误差校验器,可消除偏差,从而得到更准确的注意力评分。
通俗来说,TurboQuant本质上是在不改变AI模型核心结构的前提下,对AI模型进行压缩,而且不需要预处理,也无需专门的校准数据。
谷歌称,他们基于开源长上下文模型(Gemma和Mistral),并在LongBench、Needle In A Haystack、ZeroSCROLLS、RULER以及L-Eval等多项基准测试中,对TurboQuant、PolarQuant和KIVI三种算法进行了严格评测。
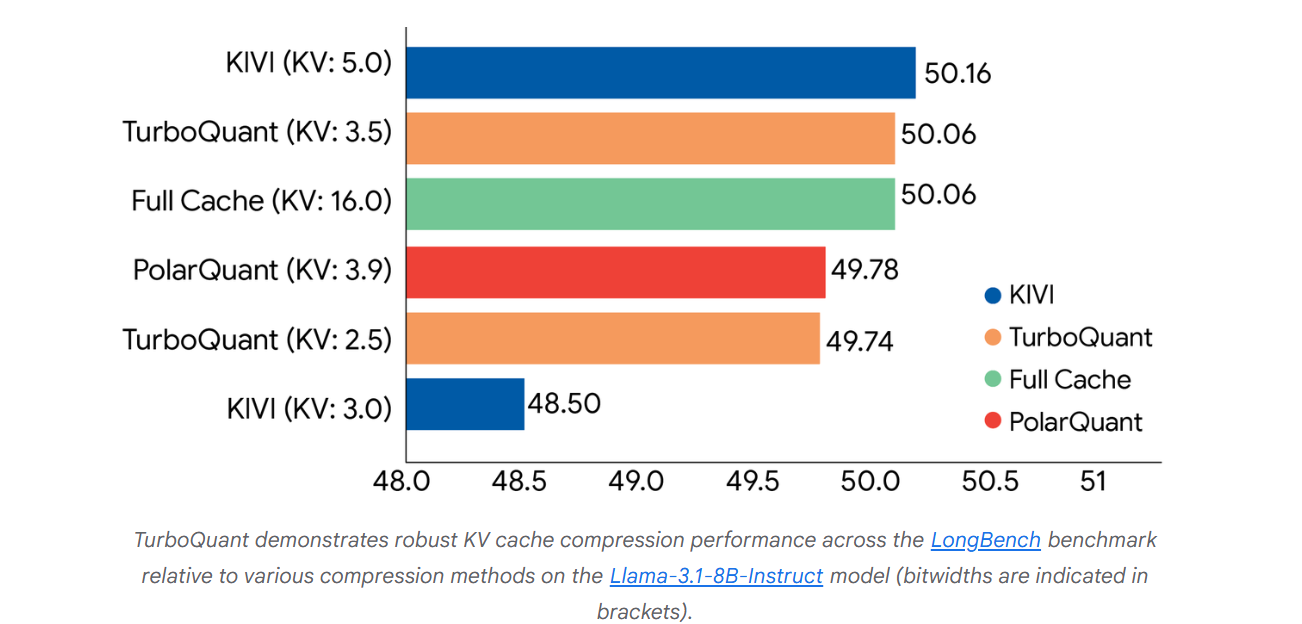
实验结果显示,TurboQuant在点积失真和召回率两项指标上都取得了最佳得分,同时尽可能压缩了键值(KV)内存占用。
上图展示了TurboQuant、PolarQuant和KIVI基线算法在问答、代码生成以及摘要等不同任务中的综合表现得分。
谷歌表示,TurboQuant在全部基准测试中都取得了理想的下游结果,同时将键值内存规模至少压缩了6倍。
他们计划在下个月举行的ICLR 2026会议上展示这项研究成果,并介绍实现这一压缩效果的两种方法:量化方案PolarQuant以及名为QJL的训练和优化方法。
谷歌迎来DeepSeek时刻?
谷歌这项算法,让不少人联想到HBO电视剧《硅谷》(2014年至2019年播出)中的虚构创业公司Pied Piper。在剧中,Pied Piper同样研发出一种突破性的压缩算法,能够在接近无损的情况下大幅缩减文件体积。
而现实中的谷歌研究团队推出的TurboQuant技术,同样追求在不损害质量的前提下实现极致压缩,只不过它瞄准的是人工智能系统中的核心瓶颈。
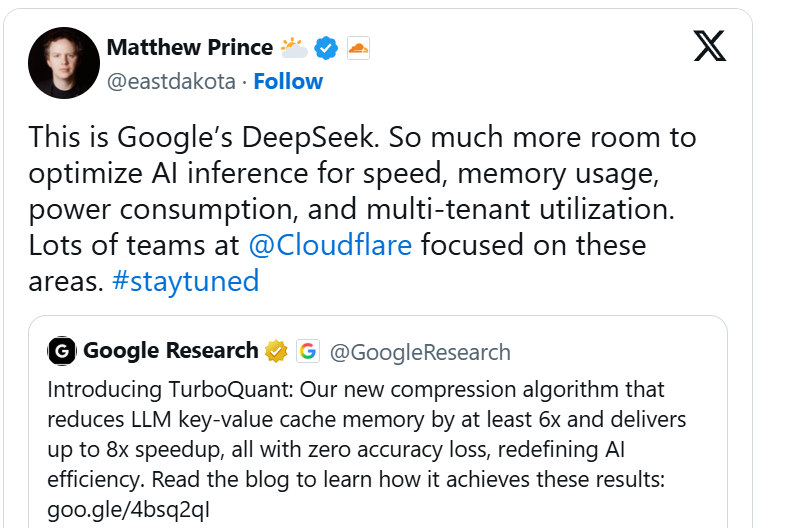
Cloudflare首席执行官Matthew Prince等人甚至将其称为谷歌的DeepSeek时刻,认为它有望像DeepSeek一样,依靠极高的效率增益显著降低AI运行成本,同时维持结果层面的竞争力。
他在X平台的一篇帖文中写道:“在速度、内存占用、功耗和利用率这些方面,AI推理仍有很大的优化空间。”
内存芯片需求将会降温?
谷歌发布这项算法之时,全球存储芯片短缺问题也正变得愈发严峻。
由于全球科技巨头正全力加码AI基础设施建设,内存需求持续上升,供需失衡短期内难以扭转。各大科技公司的开发者已经尝试多种创新办法,以克服或至少缓解内存紧张,而在科技界看来,谷歌的TurboQuant很可能成为一种可持续的“内存降温”方案。
这一预期对于大举布局AI基础设施的科技巨头而言,显然是利好消息。但对内存芯片制造商来说,影响可能就没那么乐观了。
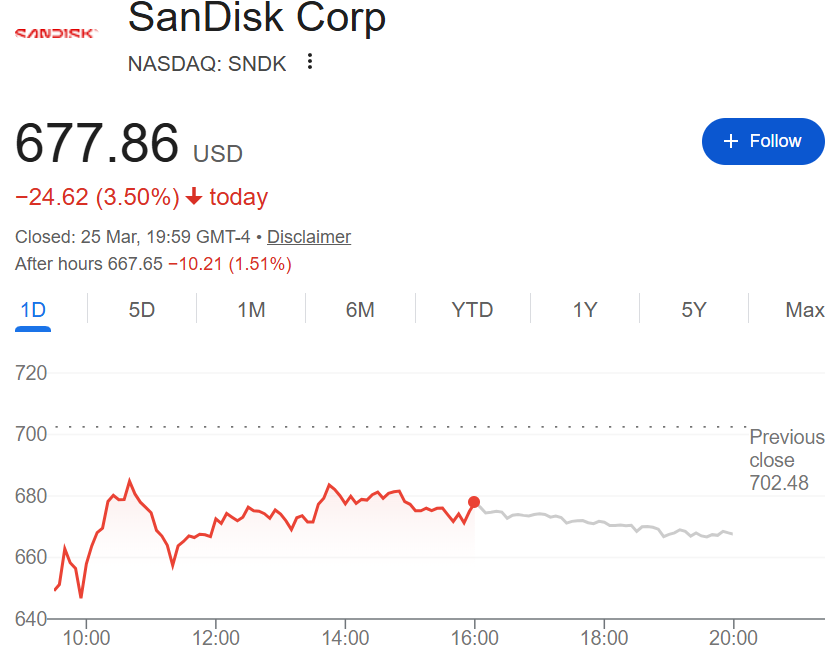
受内存需求可能降温预期影响,美东时间周三,美股存储芯片板块开盘后不久便集体下跌:闪迪一度跌6.5%,美光科技跌4%,西部数据跌超4%,希捷科技跌超5%。
周四亚洲交易时段,截至发稿时,SK海力士下跌4.42%,三星跌3.02%。
Futurum股票研究部门的Shay Boloor表示:
“市场认为,这对内存类股票构成潜在利空,因为长上下文AI推理在每个工作负载上的内存需求,现在可能会明显下降。”
大摩提出相反观点
不过,也有华尔街机构给出了截然不同的判断。
例如,Lynx Equity Strategies分析师KC Rajkumar就认为,TurboQuant所谓的技术“颠覆性”或许并不像媒体描述得那样夸张。
他指出,谷歌所称的“8倍性能提升”是基于与较老的32-bit模型进行对比,但当前推理模型早已广泛采用4-bit量化数据,因此实际性能提升并没有外界想象得那么惊人。
此外,摩根士丹利还表示,谷歌的TurboQuant技术只作用于推理阶段的键值缓存,并不会影响模型权重占用的HBM,也与训练阶段无关。
因此,这并不意味着整体存储需求或硬件总量减少了6倍,而更像是通过效率优化提高单GPU吞吐能力——同样的硬件可以支持4至8倍更长的上下文,或在不触发内存溢出的情况下显著扩大批处理规模。
更关键的是,摩根士丹利进一步引用了“杰文斯悖论”(Jevons Paradox),以说明其认为内存需求不会明显降温的原因。
杰文斯悖论是经济学中的一个重要概念,用来描述技术进步与资源消耗之间看似反直觉的关系。其含义是:当技术进步提升了效率后,资源消耗不但未必下降,反而可能快速增加。比如,瓦特改良蒸汽机后,煤炭使用效率提高了,但煤炭需求最终却大幅攀升。
摩根士丹利认为,TurboQuant通过显著压低单次查询的服务成本,可以让过去只能运行在云端昂贵集群上的模型逐步下沉到本地,降低AI大规模部署门槛,这反而可能进一步抬升整体需求。
事实上,Cloudflare首席执行官Matthew Prince等人提到的DeepSeek,就是杰文斯悖论最典型的案例:去年年初DeepSeek刚发布时,市场也曾担心AI硬件需求会降温,但实际情况是,效率提升推动了AI应用进一步普及,AI硬件需求也再度升温。