谷歌论文学术争议:中国学者揭露方法相似性回避
记者|王明
3月26日,谷歌研究院(Google Research)发布的一篇论文引发全球存储芯片市场震荡,导致美韩企业市值损失超900亿美元。
谷歌论文称,名为TurboQuant的新算法可在不降低准确性的前提下,将AI大模型KV缓存内存占用压缩至原1/6。
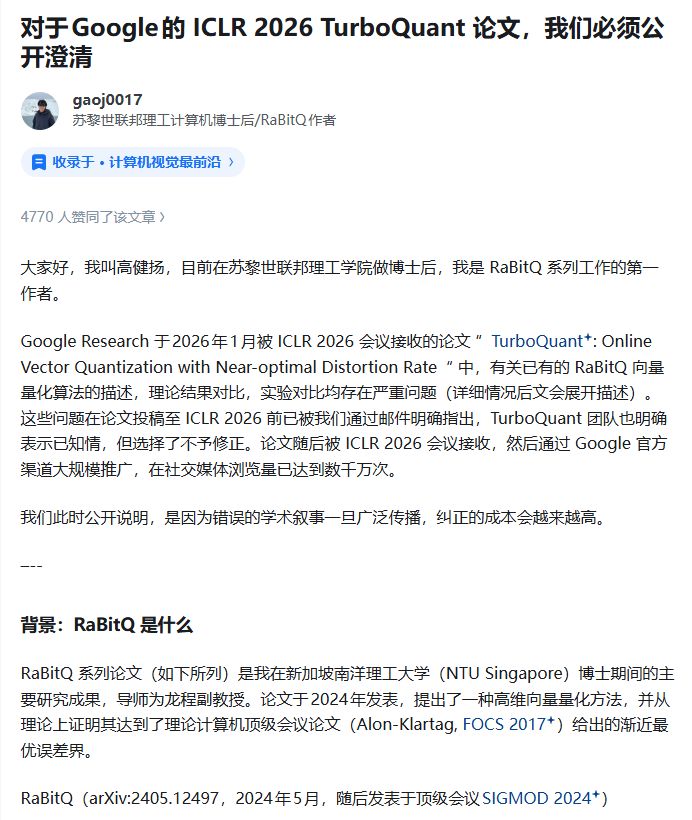
仅一日后,苏黎世联邦理工学院博士后高健扬在社交平台发文,指出谷歌论文存在重大学术问题。
高健扬表示,谷歌回避了TurboQuant算法与2024年他在新加坡南洋理工大学(NTU)博士期间提出的RaBitQ方法的相似性,并错误阐述了RaBitQ的理论成果,还故意设置不公平实验条件。
RaBitQ是一种向量量化技术,可在高度压缩下保障向量数据的搜索可靠性。
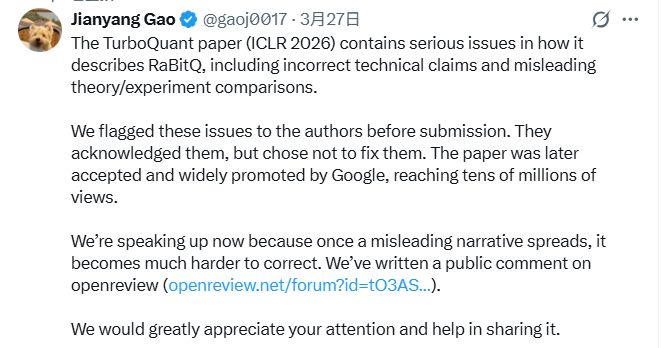
高健扬还称,谷歌TurboQuant团队“知错不改”。在谷歌论文2025年4月正式发表前,他已通过邮件指出上述问题,但谷歌方在知情后仍未在最终版本中彻底修正。
3月29日,《每日经济新闻》记者(以下简称NBD)对RaBitQ论文作者高健扬和龙程进行了采访。
RaBitQ是高健扬在新加坡南洋理工大学攻读博士学位期间的核心成果,龙程担任其博士生导师。
此外,《每日经济新闻》记者向谷歌发送了采访请求,但截至发稿时未获回应。据悉,谷歌研究院计划于4月举行的2026年国际学习表征会议(ICLR 2026)上展示TurboQuant论文。
NBD:你们最初是什么时候发现谷歌TurboQuant论文存在问题的?
高健扬:早在2025年1月,TurboQuant论文的第二作者Majid Daliri就主动联系了我们,请求协助调试其基于RaBitQ C++代码翻译的Python版本,并提供了详细的复现步骤和报错信息。这表明TurboQuant团队对RaBitQ技术细节有充分了解。
2025年4月TurboQuant论文发布后,我们注意到该论文中对RaBitQ的描述存在严重失实——将RaBitQ描述为grid-based PQ(基于网格的乘积量化),完全忽略其核心的随机旋转步骤,同时在无任何推导或证据的情况下将RaBitQ的理论保证定性为“次优”,实验对比也存在明显不公平设计。
我们的第一反应是困惑和遗憾:TurboQuant与RaBitQ的技术相似性清晰可见,而对方对RaBitQ的了解程度远超一般读者,这种情况下出现系统性失实描述,很难用疏忽解释。
NBD:在公开发声前,双方团队有哪些沟通?
高健扬:我们进行了多轮沟通,时间跨度超过一年。
2025年5月,我们通过邮件与Majid Daliri就实验条件差异和理论结果最优性进行了详细技术讨论,逐条澄清了TurboQuant团队的错误解读,Majid Daliri明确表示已将讨论结果告知全体共同作者。
然而,在我们要求修正论文中的事实性错误后,他停止了回复。
2025年11月我们发现TurboQuant已提交ICLR 2026(2026年国际学习表征会议),且错误内容原封未动,随即联系了ICLR 2026 PC Chairs(大会主席),但未获回应。
2026年3月论文通过谷歌官方渠道大规模推广后,我们再次正式向全体作者发送邮件。
收到的回复是:第一作者Amir Zandieh承诺修正理论描述和实验条件,但明确拒绝修正方法论相似性的讨论,且声称只愿在ICLR 2026正式会议结束之后才做修改。这一回应令我们感到失望但并不意外。对方显然清楚问题所在,却选择了最小限度的让步。
NBD:TurboQuant与RaBitQ最关键的相似之处是什么?
高健扬:两者最核心的相似之处,在于都采用了在量化前对向量施加随机旋转(Johnson-Lindenstrauss变换)这一关键设计,并利用旋转后坐标分布的统计性质来构建距离估计器。
值得注意的是,TurboQuant论文作者在ICLR OpenReview(学术圈常用的公开论文评审平台)的审稿回复中,这样描述自己的方法:“我们的实现方式是,先用向量的L2范数对其进行归一化,然后施加一次随机旋转,以确保这些向量在旋转后的各个分量服从Beta分布。”这与RaBitQ的核心机制高度吻合,但在论文正文中却从未正面说明这一联系。
可以用一个比喻来理解:假设一位厨师率先公开发表了一道菜的完整食谱,之后另一位厨师发布了一道采用几乎相同核心步骤的菜,却在介绍中将前者描述为“做法不同、效果较差的另一道菜”,对两者之间的联系只字不提。
读者在不知情的情况下,自然无法得出公正的判断。
NBD:按照学术规范,这类关系应如何处理?
龙程:学术规范要求,当一项新工作在方法论上与已有工作存在实质性联系时,应明确引用并正面讨论这种联系,包括说明新工作在哪些方面有所推进,哪些方面沿用了已有框架。
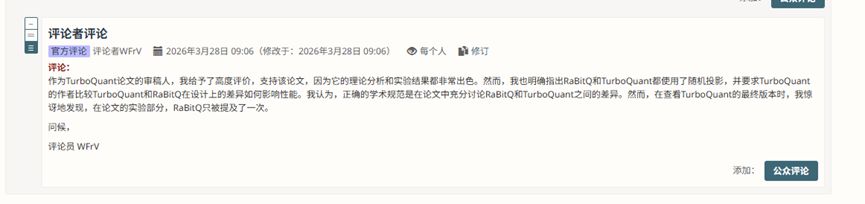
这一点在本案例中尤为重要,因为ICLR的一位审稿人也在审稿意见中独立指出“RaBitQ及其变体与TurboQuant的相似之处在于,它们都使用了随机投影”,并明确要求更充分的讨论和比较。
连审稿人都注意到了这一联系,论文作者却在最终版本中不仅没有补充讨论,反而将原本正文中对RaBitQ的不完整描述移入了附录。这种处理方式与学术规范的基本要求背道而驰。
NBD:为什么选择现在公开,而不是继续通过学术渠道内部解决?
龙程:我们并非跳过学术渠道,而是在学术渠道已基本走完的情况下选择公开。
我们先后联系了论文作者、ICLR PC Chairs(程序委员会主席),并已向ICLR General Chairs(大会主席)和Code and Ethics Chairs(代码与伦理主席)提交附有完整证据包的正式投诉,同时也在ICLR OpenReview平台发布了公开评论。
但我们也必须承认一个现实:我们是一个小型高校科研团队,对方是谷歌研究院。在资源、影响力和话语权上,双方本就不对等。
TurboQuant论文在社交媒体相关浏览量短时间内达到了数千万次,这是任何高校实验室都不可能具备的传播能力。
在这种不对等的格局下,如果我们继续沉默等待内部流程,错误的叙事只会加速固化为共识。公开发声,是弱势方在正式渠道响应迟缓时,为维护基本学术事实所能采取的为数不多的手段之一。
NBD:如果相关问题未被修正,可能带来哪些影响?
龙程:第一,它会系统性地扭曲学术史的记录,让后来的研究者误判方法论演进的源头,进而在错误的基础上构建新工作。
第二,它会打击原创性研究的激励机制。如果一项经过严格理论推导、达到渐近最优误差界的方法,可以被重新包装后以数千万曝光量推向公众,而原作者却得不到应有的认可,这对学术生态的伤害是长期且深远的。
第三,对于向量量化这一正处于快速发展阶段、工业界高度关注的领域,不准确的方法归属会直接影响从业者和研究者对技术路线的判断,导致资源的错误配置。
NBD:你们认为这属于学术分歧吗?
龙程:这已超出学术分歧的范畴。学术分歧通常发生在双方对技术内容存在真实的理解差异时。
但在本案例中,TurboQuant团队对RaBitQ技术细节的了解有充分记录;我们在2025年5月已通过邮件逐条澄清了理论保证的最优性,Majid Daliri明确表示已告知全体作者;实验条件的不对等也在邮件中得到了作者本人的承认。
在上述情况下,相关错误在论文经历投稿、审稿、接收、发表和大规模宣发的全过程中始终未被修正。我们不倾向于轻易做出定性,但我们认为,这一系列行为已经有充分的事实基础供学术共同体和相关机构独立判断。
NBD:对于像谷歌研究院这样大型研究机构,他们的责任在哪里?
龙程:大机构的背书本身会产生放大效应。一篇论文通过谷歌官方渠道推广,其传播速度和覆盖范围与普通学术论文不可同日而语。
在这种规模下,论文中的错误叙事一旦扩散,纠正所需的代价会成倍增加。我认为大机构有责任在论文对外大规模宣发之前,确保其中涉及他人工作的描述经过基本的事实核查,而不是将这一责任完全推给同行评审。
同时,当外部研究者提出有据可查的异议时,大机构也应当有正式的内部机制来处理,而非保持沉默。这既是对学术社区的责任,也是对自身公信力的保护。
NBD:你们接下来会采取进一步行动吗?
龙程:接下来,我们计划在arXiv发布详细的技术报告,系统梳理RaBitQ与TurboQuant在方法论上的关系,并对三个问题逐一进行技术层面的阐述,供学术社区参考。
我们也在考虑通过进一步的渠道向相关机构如Google Research Escalation Council(谷歌研究申诉理事会)反映。我们的目标始终是让公共学术记录准确地反映各方法之间的真实关系,而不是制造对立。