
苹果深化端侧AI战略,聚焦终端设备本地化智能处理
当前科技圈竞相投入巨资建设人工智能算力中心之际,苹果计划进一步凸显iPhone等终端设备本地运行AI模型的竞争优势。下月举行的苹果全球开发者大会上,多款延期已久的iPhone人工智能增强功能将成为核心看点。同时,苹果将重点突出一个被市场低估的AI差异化优势:借助全球庞大的苹果设备生态,实现AI模型的终端本地化运行。据熟悉大会筹备情况的人士透露,苹果有望展示其历时15年自研专用芯片的技术沉淀——从iPhone、Apple Watch到Mac系列处理器,这套技术架构能够支撑AI模型在用户设备上高效运转。行业普
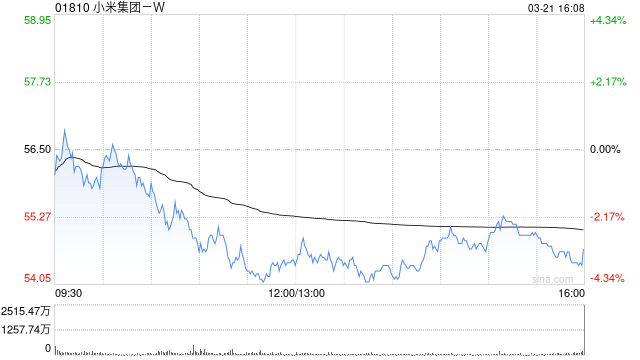
花旗维持小米集团"买入"评级 目标价定格37港元
花旗发布研究报告指出,小米集团-W(28.04, -0.52, -1.82%)(01810)宣布永久性调低"MiMo-V2.5"系列大语言模型(LLM)的API定价,降幅高达99%。该行认为,这项大胆的价格调整措施于5月27日起在全球范围内推行,旨在与同行业竞争者保持同步。花旗维持其"买入"评级,目标价依旧为37港元。此前,DeepSeek已于四天前宣布永久性降低V4 Pro API定价,降幅达75%。小米管理层在5月26日举行的业绩说明会上曾披露,其AI业务收入主要来源于词元(token)消耗,其中Mi
企业AI智能化转型:模型训练与定制系统开发实战指南
在人工智能技术飞速发展的今天,企业对智能化能力的需求已超越简单的API调用,转而追求与业务逻辑的深度融合。真正的竞争优势源于能够精准理解特定业务场景、并与现有流程无缝衔接的定制化智能系统。这种能力的核心在于AI模型训练与全栈定制化系统开发的深度结合。在AI模型训练的完整生命周期中,虽然算法先进性至关重要,但数据质量与工程化处理能力往往决定了模型的最终上限。定制化AI开发的起点并非选择算法,而是对业务数据进行深度挖掘与标准化构建。针对特定行业场景,原始数据通常呈现高度碎片化、噪声大、维度不统一等特点。定制化
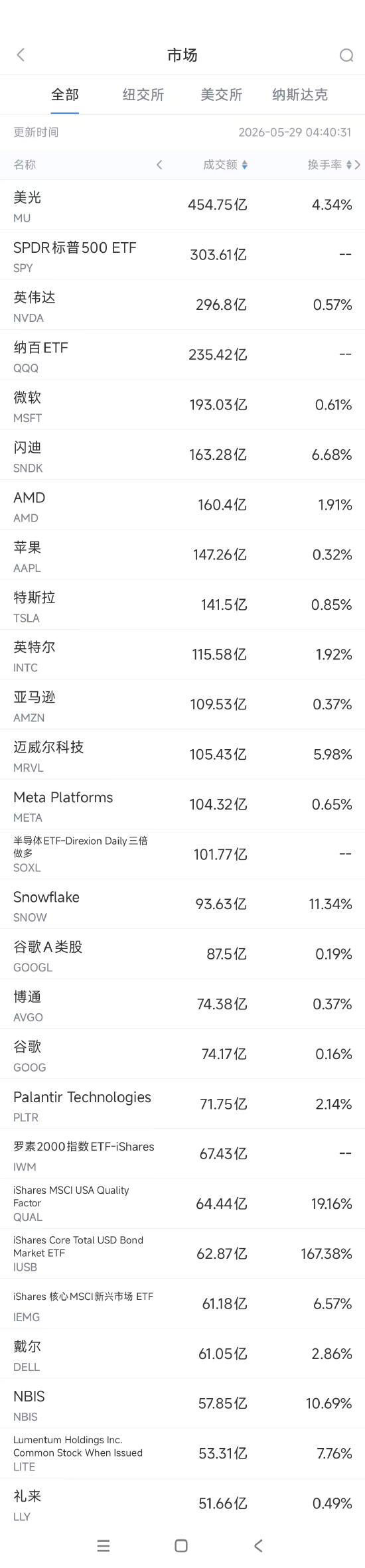
美股成交额榜单:微软下周推自研AI模型,英伟达黄仁勋访韩
周四美股成交额榜首的美光科技微跌0.53%,收报454.75亿美元。尽管股价微跌,但鉴于其过去一年暴涨684%且受益于AI芯片需求与存储周期复苏,未来仍有巨大的上涨空间。分析师指出,公司二季度业绩远超预期,并给出了强劲的三季度指引,助力其市值突破万亿。高带宽内存(HBM)技术正在重塑存储行业的盈利模式,让美光从周期性供货商转型为基础设施企业。通过签署五年期战略客户协议(SCA),美光锁定了长期出货与定价,显著提升了未来盈利的稳定性。 位居第二的英伟达股价上涨0.78%,成交296.8亿美元。此前已连续四日
微软即将在Build大会推出全新编程AI模型
据The Information引述知情人士透露,微软将在下周举办的年度Build开发者大会上推出一系列全新AI模型。 微软计划发布一款代码生成模型,旨在增强GitHub Copilot的市场竞争力。 同时,微软还将宣布多款不同规模的新模型,涵盖语音识别、逻辑推理、语音合成以及图像处理等多个技术领域。

微软Build大会将发布多款自研AI模型
微软定于下周在旧金山举行的Build开发者大会上,发布一系列自主研发的人工智能模型,旨在赢得开发者的青睐。 据知情人士透露,微软计划推出一款专注于代码的专用模型,旨在增强旗下代码助手GitHub Copilot的市场竞争力。尽管该工具在AI代码辅助领域曾占据先机,但目前的份额正逐渐被Cursor与Claude Code瓜分。 该知情人士还称,微软将推出多种不同参数级别的全新模型,分别应用于语音转写、逻辑推理、语音处理及图像生成等场景。这些新模型是基于微软今年早些时候对外展示的模型迭代升级而来。正如斯蒂芬妮
全球首例!国产AI自主构建新一代智能模型
2026年5月27日,全球AI领域迎来里程碑时刻!没错,电影中“AI自我进化、自主创造”的场景,如今在中国成为现实!中国AI企业面壁智能正式宣布:全球首个完全由AI自主研发、无需人工编写核心代码的AI模型成功问世!从构建训练框架到产出全新模型,整个流程均由AI独立完成。这不仅是技术上的重大飞跃,更重新定义了全球AI研发的基本范式!核心亮点:AI造AI,全流程闭环(无手写代码)此次突破并非“AI辅助编码”级别的改进,而是建立了一套完整的工业级自动化流程。三大关键组件构成了完美的自主进化体系:ForgeTra
AI自主构建AI:技术闭环的起点
↓↓↓点赞、转发、关注、获取更多AI实战干货!↓↓↓最近我注意到,AI领域发生了一件令人深思的事。不是因为某个模型性能提升,而是一个完整的自动化流程在2026年5月26日被一家中国公司悄然实现。事件核心非常清晰:执行方:面壁智能,联合清华大学与OpenBMB开源社区。成果内容:推出了端侧大模型MiniCPM5-1B,并开放了其训练框架ForgeTrain的源码。(AI独立造出了AI)最引人注目的地方在于ForgeTrain这套框架——这些代码完全由AI自动生成,而该框架又成功训练出新的AI模型。这个过程让
清华五道口AI速递 | 多款大模型齐发,端侧AI密集落地,人形机器人同步更新
各位早安!欢迎收听清华五道口AI速递,每日为您梳理AI领域最新动态。OpenAI GPT-5.6意外泄露:上下文窗口扩至150万token,预计6月亮相2026年5月26日,多位开发者在OpenAI Codex后端日志中发现了尚未公开的下一代模型线索,内部代号为“iris-alpha”,外界猜测即为GPT-5.6。该模型最大亮点在于上下文窗口从GPT-5.5的105万token大幅提升至150万token,增幅约43%,可更高效处理超长文档、大型代码库及复杂多步骤任务。测试表明,即使输入超过90万toke
数据中台:AI时代的智能中枢系统
自2023年ChatGPT引发智能热潮以来,各类大模型如雨后春笋般涌现,Sora、Gemini及国内大模型纷纷登场,似乎人类在一夜之间迈入了“AI无处不在”的时代。人们热烈讨论算法的精妙、算力的高昂成本,却往往忽略了最根本的问题:这些无所不能的AI,究竟是如何“吃饱”的?答案就藏在看似平凡的“数据中台”概念中——它就像AI工厂的“中央厨房”。没有它,再精妙的算法也只是空转,再强大的算力也只能干瞪眼。假设你开了一家面馆。后厨是堆满各种食材的大仓库——鸡蛋、牛肉、调料等,这就是你的原始数据,散落在各个业务系统
AI快讯:GPT-5.6悄然现身;昆仑万维推出SkyClaw-v1.0;阿里Qwen3.7-Max编程实力全球第二
1、上下文 150 万 tokens!OpenAI未官宣新旗舰GPT-5.6意外曝光2、国产模型大突破!昆仑万维发布天工高性能 Agent 模型 SkyClaw-v1.03、阿里 Qwen3.7-Max 编程能力全球登顶第二!Code Arena 1541 分,仅次 Claude4、商汤 Seko AI 再进化:发布生产链路 Seko Space,加速漫短剧工业化布局5、Hyper3D Rodin Gen-2.5 发布:4 秒百万面、全球首款千万面级 3D 生成模型,细节直逼生产级资产6、AI“治安官”上
AI重大进展:GPT-5.6提前曝光,OpenAI秘密筹备上市,六月模型大战即将打响
今日最震撼的消息,莫过于GPT-5.6的意外泄露。多位开发者在OpenAI Codex后端日志中,发现了一个尚未公开的模型——代号为“iris-alpha”的GPT-5.6。最令人震惊的是其参数表现:上下文窗口直接扩展到150万Token,相比GPT-5.5提升了约43%。这表示它能够一次性处理整本书或整个大型代码库,并在无提示条件下,直接生成具备商用级设计水平的前端界面。有开发者称其为“UI去垃圾化”能力的质变。同时,多方消息显示,今年6月将迎来历史上最密集的顶级模型发布潮。Anthropic的Clau
AI公司如何通过开源模型盈利?
最近关于大模型开源与闭源的消息频出,你是否也有类似疑问:随着越来越多的AI模型选择开源——参数公开、可免费下载甚至支持商用,那么这些开发AI模型的企业究竟如何维系运营?本文将探讨AI企业的盈利方式。目前来看,开源模式主要有三种不同的路径。闭源模型(如GPT-4、Claude):类似可口可乐的秘方,只能通过API调用,按使用量计费,不公开模型细节。开源模型(如DeepSeek、Llama):就像公开的菜谱,用户可以自由下载代码和参数,并在自己的硬件上运行或进行修改。过去,开源模型在性能上可能稍显逊色,价格便
AI行业动态 | 2026.05.26
消息:DeepSeek公布其1.6万亿参数模型V4-Pro的API服务,自5月31日优惠期结束后,将以原价25%的折扣长期执行。输入费用调整为0.435美元/百万token,缓存命中成本减少90%。此外,公司内部成立Harness团队,专注开发代码智能体产品,与Anthropic的Claude Code形成直接竞争。重点观察:消息:5月19日,OpenAI联合创始人Andrej Karpathy确认加盟Anthropic预训练部门,将带领团队“借助Claude提升预训练研究效率”。同期,Anthropic
AI模型训练指南:从入门到实践
构建专属AI模型的关键步骤包括:确定目标→准备数据→选择合适模型→训练优化→部署更新;初学者建议采用PyTorch或TensorFlow框架配合云GPU资源及预训练模型微调技术,投入较少但效果显著。任务分类:首先明确方向 —— 图像识别分类/检测、文本分析生成/分类、语音信号识别、数值预测等。评估标准:分类任务关注精确度/召回率/F1值;回归任务关注平均绝对误差/均方根误差;生成任务关注困惑度(PPL)/BLEU指标。资源配置:个人及小团队建议在预训练模型基础上进行微调(BERT/ResNet/Llama