杀疯了!DeepSeek V4将百万上下文压至2毛,联手华为昇腾,国产算力要掀桌子?
文丨《BUG》栏目 周文猛
DeepSeek-V4预览版,正式亮相了。
今日,DeepSeek官方正式宣布:具备百万字超长上下文理解能力的deepseek-v4-pro与deepseek-v4-flash两款模型已上线并开源,即日起用户可通过官网或官方App体验最新版DeepSeek-V4对话功能,感受1M(百万)级超长上下文记忆的新突破,API服务也已同步升级。
根据官方公布的基准测试结果,在上下文处理、知识储备、逻辑推理及智能体等核心能力上,DeepSeek V4的性能已可与国际顶尖闭源模型相媲美,达到了国际开源模型的顶级水准。《BUG》栏目对比发现,在API调用成本方面,去年凭一己之力引发国内大模型行业价格战的DeepSeek,此次V4版本再度报出了行业“地板价”。
“尽管每百万Tokens的调用费用国内各家模型都未大幅下调,但凭借超长的上下文窗口和强劲的性能表现,其市场竞争力依然十分突出!”有业内专家向《BUG》栏目表示:“那个大模型市场的价格杀手,又回来了!”
性能对标顶级闭源模型,知识推理全面领跑
据DeepSeek官方资料显示,V4系列包含两个版本:DeepSeek-V4-Pro总参数量达1.6T、激活参数49B,预训练数据量33T;DeepSeek-V4-Flash总参数量284B、激活参数13B,预训练数据量32T;两款模型均原生支持100万token上下文窗口。
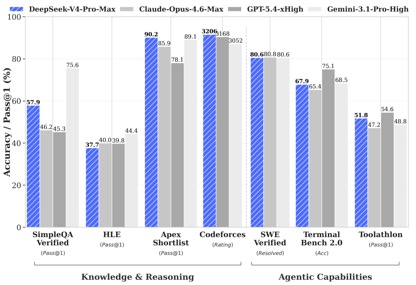
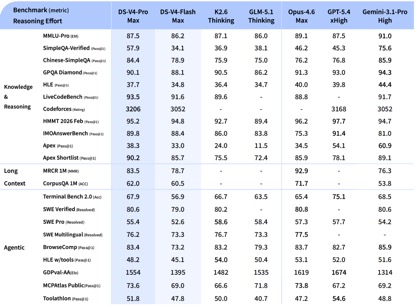
根据DeepSeek公开的测试数据,在知识与推理类任务中,DeepSeek-V4-Pro-Max在Apex Shortlist和Codeforces两项评测中斩获最佳成绩,超越了Claude-Opus-4.6-Max、GPT-5.4-xHigh、Gemin-3.1-Pro-Hight等国际主流模型,展现出卓越的逻辑与算法实力;在SimpleQA Verified测试中虽略逊于Gemini-3.1-Pro-High,但仍领先于Claude和GPT系列。
在智能体能力评估中,V4、Opus-4.6、Gemin-3.1-pro三款模型在SWE Verified任务上表现持平,且DeepSeek在Toolathlon任务中仅次于GPT-5.4-xHigh,在Terminal Bench 2.0上更是优于Opus-4.6,显示出在复杂指令执行与工具调用方面的独特优势。
目前DeepSeek-V4已成为公司内部员工日常使用的智能编码助手,根据内部评测反馈,其使用体验已超越Sonnet 4.5,代码交付质量接近Opus 4.6的非思考模式。
在数学、STEM学科及竞赛级代码生成等测评中,DeepSeek-V4-Pro的表现已超越当前绝大多数已公开评测的开源模型,成绩足以比肩世界顶尖闭源模型。
总体来看,在知识处理与逻辑推理层面,DeepSeek-v4相较国内开源模型实现了全面超越,测试成绩已与国际一流水平看齐。不过在智能体能力方面,尽管新版DeepSeek-v4进步显著,但相较国内外第一梯队尚未形成绝对优势,各方在不同场景下各有胜负。
“标配”百万级上下文,价格杀手强势回归
相较于各项基准测试展现的性能提升,本次V4发布最引人注目的亮点,无疑是长文本处理的突破性进展以及API调用成本的再度降低。
依托DeepSeek-V4创新的注意力机制,V4通过在token维度实施压缩并结合DSA稀疏注意力(DeepSeek Sparse Attention),实现了全球领先的长上下文处理能力,且相比传统方案显著降低了计算与显存消耗,将1M(百万级)上下文能力升级为DeepSeek全系列官方服务的标准配置。
一年前,百万级上下文还是Gemini的独门绝技,即便是最近发布的多数国产主流开源模型,其上下文长度也多集中在128K—200K区间,而DeepSeek直接将百万上下文从“高端闭源专属”变成了“开源标配”。
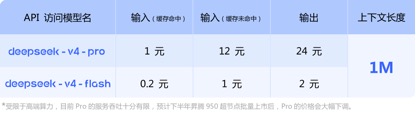
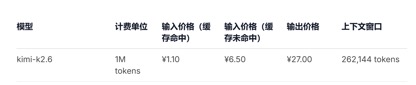
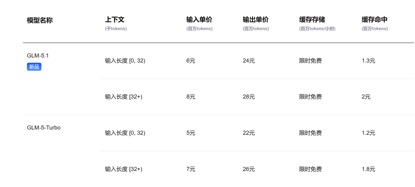
在API定价方面,对比当前GLM-5.1输入单价1.3元-2元/百万Tokens(缓存命中),以及Kimi-K2.6的1.1元/百万tokens(缓存命中),DeepSeek-v4-pro与flash两个版本的输入单价分别仅为1元/百万tokens及0.2元/百万tokens,虽降幅不算惊人但已处于行业最低水平,且上下文长度实现了数倍扩展。
(DeepSeek-v4系列模型API调用价格)
(Kimi-k2.6模型API调用价格)
(GLM-5.1模型API调用价格)
“DeepSeek-v4此次带来的性能突破,相比DeepSeek-R1发布时的震撼效应略有减弱,各项性能仍处于第一梯队,但并未完全拉开差距。”业内人士分析认为,“本次V4模型的推出,核心看点在于长文本能力的跃升与成本的持续下探。”
该专家感叹道:“此前DeepSeek-V3及R1模型发布后,其底层技术创新带来的性能红利直接引爆了国内大模型行业的集体降价潮,虽然此次V4版本每百万Tokens调用价格相较国内友商并未大幅跳水,但依然极具杀伤力,那个价格杀手又回来了!”
“下半年华为算力批量上线,Pro版价格将大跳水”
值得注意的是,在DeepSeek-v4 API价格公示页面的底部,官方特别注明:“受限于高端算力供应,目前Pro版本的服务吞吐量极为有限,预计下半年昇腾950超节点大规模量产后,Pro版本价格将大幅下调。”
这意味着,此次发布的v4系列模型已完成对华为昇腾950超节点的适配,待昇腾950正式上市后,广大用户即可基于国产算力体验到比肩国际顶级闭源模型的DeepSeek-v4。
在官方开源的技术白皮书里,DeepSeek也明确提到,v4已在NVIDIA GPU和HUAWEI Ascend NPUs平台上验证了细粒度的EP(专家并行)策略,相比强大的非融合基线,在通用推理任务中可实现1.50-1.73倍的提速,而在对延迟敏感的场景(如强化学习推演和高频代理服务)中更可达成1.96倍的加速效果。
V4发布后,华为昇腾同步官宣“超节点全系列产品已支持DeepSeek V4系列模型”。据悉,昇腾950通过融合kernel与多流并行技术有效降低了注意力机制的运算与访存成本,显著提升了推理效率,结合多种量化压缩算法,成功实现了高吞吐、低延迟的DeepSeek V4模型推理部署。
本月早些时候,英伟达CEO黄仁勋在接受Dwarkesh Patel专访时曾表示:“若DeepSeek率先在华为平台发布,那对我们国家(美国)将是灾难性的。”在黄仁勋看来,尽管DeepSeek属于开源模型,同样可在英伟达硬件上运行,但若其专门针对华为算力做深度优化,在高端算力采购受限的背景下,英伟达将陷入被动局面。
如今看来,尽管DeepSeek也针对英伟达算力验证了EP方案,但黄仁勋担忧的情形正在成为现实。业内人士指出:“V4是算力博弈倒逼出的创新产物,未来一年内,国产大模型在国产芯片上跑通将日趋成熟。”
多模态功能依然缺席
略有遗憾的是,DeepSeek V4虽已发布,但仍是一款纯文本模型,并未集成文生图、文生视频等多模态能力。这也让普通用户快速评测体验一款模型增加了不少门槛。
毕竟,在大语言模型能力持续进化、幻觉问题逐步改善的今天,常规单一的知识问答已难以客观评判一款模型的真实水准。对多数用户而言,想要真切感受V4的实力,还需下载并深度使用一段时间。
伴随V4系列模型的发布,近期市场还传出DeepSeek计划融资500亿元的消息,据接近DeepSeek的知情人士透露,DeepSeek投前估值已达3000亿元(约440亿美元),目前腾讯控股、阿里巴巴集团均在接洽投资事宜。不过针对融资传闻,DeepSeek方面迄今未向媒体作出正面回应。
或许,对DeepSeek创始人梁文锋而言,在全球大模型“智力”增长放缓、行业人才争夺白热化、多模态与Agentic化趋势日益明显的当下,借V4发布之机适时融资以壮大自身实力,也不失为一招妙棋。
责任编辑:张乔松
新浪财经声明:此文系转载自合作媒体,新浪财经刊载此文旨在传递更多信息,文章内容仅供参考,不构成投资建议。
郑重声明:1.依据《证券法》规定,禁止编造、传播虚假信息或误导性信息,扰乱证券市场秩序;2.用户在本社区发布的所有资料、言论等均属个人观点,与本网站立场无关,不构成任何投资建议。用户应基于自身独立判断,自主作出证券投资决策并承担相应风险。