昇腾950超节点荣获2026世界人工智能大会SAIL大奖
2026年全球人工智能大会(WAIC)在上海盛大举行。主论坛公布了大会最高奖项——卓越人工智能引领者奖(Super AI Leader,简称SAIL大奖),昇腾950超节点(Atlas 950 SuperPoD)因其系统架构的创新与突破,从众多国内外参评项目中脱颖而出,成功摘得SAIL大奖。昇腾950超节点喜获SAIL大奖世界人工智能大会(WAIC)作为全球AI领域的顶尖盛会,始终致力于探索人工智能技术前沿并驱动行业创新发展。SAIL奖(Super AI Leader Award)代表着WAIC的最高荣誉
视界|AI 新纪元:安全与落地成核心,监管服务开启新篇章
安全对齐超越模型迭代,AI 应用战迈入服务与监管新纪元2026 年 7 月 16 日 星期四今日 AI 领域传递出明确的结构性信号:当模型能力趋于稳定,决定产业格局的不再是基准测试分数,而是"谁能实现模型真正落地"。OpenAI 借 GPT-Red 将"自我对抗"转化为新基建,Thinking Machines 以 Inkling 开源权重模型回应"通用未必最强"的命题,Anthropic 携手 Blackstone 豪赌"AI 实施"为下一
AI 大模型能超越人类智慧吗?
本期访谈邀请到人工智能领域的先驱者、早在上世纪 80 年代末便发明卷积神经网络的顶尖专家杨立昆 Yann LeCun。若您时间有限,建议先点赞收藏并关注。大语言模型的发展正触及瓶颈;硅谷巨头们鼓吹的“仅靠扩大模型规模即可实现通用人工智能(AGI)”,很大程度上是为了获取持续投资而构建的虚假叙事。一、大模型为何显得愈发聪慧?大众常觉得大模型近期突飞猛进。回想早期,若将复杂的财务报表交予它,或让其起草商业计划书,它常产生严重幻觉,输出结果不堪入目。但如今,情况显著改善,表现已相当出色。这种业务能力的跃升,并非
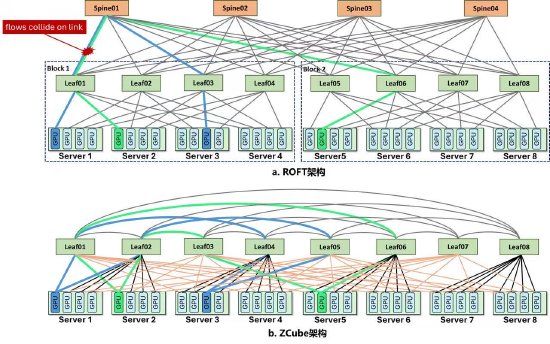
智谱AI实现Infra架构新突破 同比性能提升15%
新浪科技讯 5月21日,智谱AI在推理架构上取得重要进展,其新推出的ZCube技术可提升大模型的处理效率。实测数据显示,在相同的硬件配置下,ZCube架构能够将网络带宽从200Gbps提升至400Gbps后,推理吞吐量提升约10%,首响时延下降19%。这一改进在GLM-5.1模型的千卡级集群中得到验证,对比传统ROFT架构,GPU平均推理吞吐量提升了15%以上,同时TTFT P99尾部时延降低了40.6%。在不改变GPU、服务器或代码的情况下,仅通过架构升级,即可实现推理效率的提升。在相同的GPU型号、软
国产顶尖AI模型对决:DeepSeek-V4与GLM-5.1的科研应用深度剖析
智谱AI旗下Z.AI研究部门低调推出了新一代面向长周期智能体任务的旗舰模型GLM-5.1,该模型拥有7540亿参数。就在不久前,DeepSeek正式发布了其第四代旗舰系列DeepSeek-V4,其参数量达到1.6万亿,并将百万级超大上下文窗口设定为所有官方服务的标准配置。从科学研究的角度审视,不能仅凭其在标准化对话中的主观感受来评判,必须将其置于严苛的跨学科基准测试环境中。科研任务的复杂性要求模型必须同时具备处理高维偏微分方程的数理逻辑推演能力、在海量基因序列或学术文献中进行无损信息提取的检索能力,以及在
人工智能动态简报
System.Date: 2026-04-21模型争议:Claude 技术细节遭曝光,引发业界质疑声浪。算力瓶颈:Mythos 算力难以支撑高估值,面临现实考验。市场情绪:万亿估值依托末日恐慌,资本逻辑遭受挑战。架构创新:清华大学携手 Moonshot AI 共同发布 PrfaaS 架构,助力大语言模型推理效能升级。技术突破:通过预填充与解码分离策略优化算力配置,突破硬件制约。性能提升:显著增强模型服务表现,降低推理响应时间。核心升级:华为 Sound X5 首次深度融合 AI 大模型,实现从听觉交互到智
“龙虾”算力挑战:需求激增与供给瓶颈
在“龙虾”挥舞的双钳之下,一个巨大的算力黑洞逐渐显现。 有机构计算发现,相较于传统聊天机器人,智能体的Token(词元)消耗可增加数十倍,即使是稍复杂的任务,其背后的算力消耗也可能达到普通对话的百倍甚至千倍。科技博主实测显示,若将“龙虾”作为生产工具广泛使用,一周的费用可能接近万元。 数据清晰地反映了这一趋势。“养虾”热潮兴起后,模型调用量迅速攀升。全球API聚合平台OpenRouter的数据显示:3月16日至22日,全球大模型调用量已达20.4万亿Token,一周内增长超过两成。其中,中国大模型的周调用
AI与算力网络的相互促进:第二十八讲
AI精品通识课第二十八讲:AI与算力网络的相互促进大规模AI模型的发展正在重新定义科技行业的竞争格局,算力网络作为支撑这些大模型训练和推理的关键基础设施,其性能和规模直接影响了AI技术的进步。无论是国际上的GPT系列、Gemini等主流大模型,还是国内的DeepSeek等优秀模型,它们的万亿级参数训练和高效推理都离不开超大规模算力集群和高性能网络的支持。传统算力组网模式在带宽、规模和效率上存在显著局限,难以满足大模型参数量急剧增长带来的通信需求。如今,算力网络已从简单的硬件互连升级为一个集“架构创新+流量