SkillOpt-Lite:一行指令实现智能体高效自我进化
2026年07月09日星期四SkillOpt-Lite: 通过简单指令实现更优更快的智能体自我进化🤗 17针对现有智能体技能优化方法流程复杂的问题,本文提出一种基于零阶优化的最小可行框架SkillOpt-Lite。其核心是三个确保收敛与泛化的原则:基于文件系统的轨迹探索、共识属性挖掘和独立验证门控。该方法不仅加速收敛,且在多个模型上超越完整版SkillOpt,例如将GPT-5.4-nano的性能提升至超越标准SkillOpt优化的GPT-5.4。该框架已集成至VSCode Copilot等生产环境,开发者
腾讯再揽OpenAI人才 聚焦视觉语言模型
OpenAI人才持续外流。据《澎湃新闻》披露,前OpenAI研究员田永龙已加入腾讯大模型团队,将投身VLM(视觉语言模型)的研发工作,这已是腾讯第二次从OpenAI引进人才。公开履历显示,田永龙在OpenAI期间主要钻研计算机视觉、视觉表征学习及生成式模型。此前,他也曾在谷歌体系内积累了丰富经验。2022年末,他入职剑桥Google Research出任高级研究科学家;2024年5月转至Google DeepMind负责视觉感知模型;同年10月加入OpenAI担任技术研究员。去年12月17日,腾讯重组大模
工信部警示AI编程软件Claude Code安全隐患;OpenAI首席未来学家辞职丨AIGC日报
1.【工业和信息化部发出关于防范AI编程工具Claude Code安全漏洞风险的警告】近期,国家工业和信息化部网络安全威胁与漏洞信息共享平台(NVDB)监测到,AI编程软件Claude Code存在严重安全漏洞隐患。Claude Code是由美国Anthropic公司研发的AI编程辅助工具,能够依据文字指令自动完成代码生成、纠错等任务。因其内部嵌入了追踪功能,会在未经用户许可的情况下向远端服务器上传用户位置、身份标识等隐私数据,波及的Claude Code版本范围为2.1.91至2.1.196。提醒各机构
美企依赖中国AI模型;物理AI第一股登陆资本市场
前OpenAI研究员加入腾讯混元团队前OpenAI研究员田永龙拟加盟腾讯,有望担任混元多模态项目负责人,专注于视觉与语言模型研发,具体职位尚在商议中。他曾与此前加入腾讯的姚顺雨在OpenAI共事。田永龙学术背景卓越,清华本科、港中文硕士、MIT博士,曾任职谷歌DeepMind与OpenAI,长期深耕视觉生成方向,多篇论文影响广泛。近年来,腾讯持续引进多模态领域顶尖人才,组建专项团队强化混元多模态技术能力。
AI应用前沿|Tool-Genesis:驱动自进化语言智能体工具创建的任务导向基准 (1/20篇) · 7月6日
2026年07月06日星期一Tool-Genesis: A Task-Driven Tool Creation Benchmark for Self-Evolving Language Agent自进化语言智能体领域正快速推进,然而其依据任务需求进行工具构建、适配与维护的能力尚缺乏系统性的评估手段。当前主流基准多受制于预先设定的规范框架,制约了系统的可拓展性与自主进化空间。本研究推出诊断型基准Tool-Genesis,致力于从接口规范性、功能准确性及下游实用价值等多元视角对智能体能力进行量化评估。该基准检
京东JoyAI-VL-Interaction:让AI学会主动感知物理世界
设想这样一个画面:独居老人在客厅意外跌倒,剧痛使他无法出声呼救。这时,他身上的智能装置或家中的监控摄像头“察觉”到了异常,人工智能无需等待任何语音指令,便自动发出警报,快速联络家人或急救部门。又或者,你正在观看一场紧张的足球赛事,当决定性进球出现的刹那,你来不及回看和提问,AI眼镜就已自动为你呈现慢镜头解析与战术说明。这些场景已非对未来的憧憬,而是京东近期开源的全球首个全栈开源视觉语言交互模型——JoyAI-VL-Interaction所试图解决的真实课题。过去两年,大语言模型的能力边界持续拓展,但主流的
AI应用论文精选|数据密集场景下代码智能体的能力边界评估
2026年06月17日星期三CODA-BENCH: 代码智能体能否应对数据密集型任务?🤗 11现有评估体系将代码能力与数据处理能力分开考量,与实际开发环境存在显著差异。本文推出首个在数据密集型环境中综合评估代码与数据智能的基准测试CODA-BENCH。它基于Kaggle平台构建Linux沙箱环境,包含1,009个任务案例,每个环境平均配置980个文件,重现真实数据规模与噪声特征。评估结果显示,即使是最先进的智能体也难以高效融合数据发现与代码执行,成功率仅为61.1%,揭示了当前智能体在数据密集型任务处理方
AI画面为何总显散乱?先掌握这8种电影构图技巧
许多人在制作AI图像或AI视频时,往往将提示词的重点放在人物、风格、光线和画质等方面:“电影感、超清、精致、赛博朋克、柔和光线、浅景深”但画面仍然容易显得松散。根本原因在于:风格决定画面质感,构图决定画面语言。同一个人物、同一个场景,采用三分法构图会显得自然、有空间感;采用中心构图会变得强势、仪式化;采用留白构图,孤独感会被放大;采用对角线构图,画面瞬间变得不稳定、充满冲突。因此,AI创作不能仅仅写“好看的画面”,还要明确“画面如何组织”。构图并非简单地把主体放进画面。构图语言要解决三个核心问题:观众首先
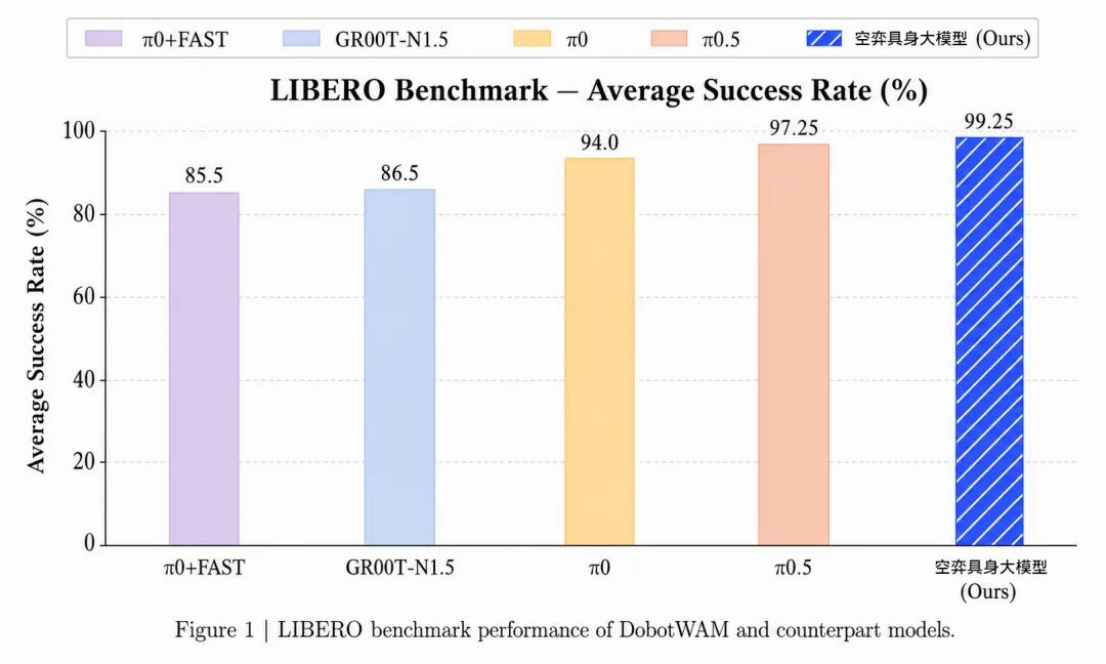
越疆科技推出空弈DobotWAM具身大模型 LIBERO评测99.25%成功率夺冠
新浪科技讯 6月1日下午消息,深圳具身智能企业越疆发布自研世界动作模型空弈DobotWAM具身大模型,该模型在具身智能标准评测基准LIBERO上分别完成LIBERO-Spatial、LIBERO-Object、LIBERO-Goal和LIBERO-10四个标准任务套件,覆盖空间关系理解、物体泛化、目标指令理解以及长时序任务执行等关键能力维度,平均成功率达99.25%,领先于π0.5、π0、GR00T-N1.5、π0+FAST等公开模型,以及业内已有数据公布的其他模型。 其中,空弈DobotWAM具身大模型
CVPR 2026 医学影像AI新风向:从图像识别迈向科研流程自动化
过去很长一段时间,医学AI领域都在探索一个核心问题:算法能否比人类医生看得更精准?因此,大量研究聚焦于病灶检测、器官分割、影像归类和报告撰写等任务,目标是在标准评测集上刷出更高的性能指标。但现在,这个问题已经不再足够。真实的医学与生命科学研究场景并非一个整洁、统一、标注完善的基准测试环境,而是由各式设备、不同协议、参差不齐的数据质量、多样的研究目标和专业背景共同构成的复杂生态。于是,研究重心开始转变。一个模型的价值不再仅仅取决于它在某个数据集上的评分,而在于它能否在新实验室的数据上迅速适应,能否仅用少量标
AI绘图不再碰运气:掌握视觉语言核心,让创作有的放矢
大家好,我是梅姐AI学习营。最近一直在体验各类AI 图像工具,比如豆包、即梦、文心一格、Midjourney等用得越久我越发现一个有趣的现象很多人刚上手 AI 图像工具,第一反应就是到处找提示词模板。好像有了模板就能解决所有问题。但是真正的高手,从来不依赖于模板。他们手中掌握的是一套可复用的创作方法论今天我想和大家聊聊,AI图像创作的底层逻辑到底是什么。一、跳出"提示词依赖症"AI 图像工具虽然在快速进化,但是有些东西是不会变的。比如说,我们对美的追求、对内容的思考、对用户的理解,始终没变
中文操控 AI 展现战略优势,清华研究揭示工程新视角
无论是优化飞机机翼还是进行各类工程设计,人工智能(AI)究竟该听中文还是英文?清华大学航天航空学院陈海昕教授团队的最新成果为此提供了答案。据《南华早报》披露,这项于 4 月底被《航空学报》收录的研究指出,相比英文指令,中文在特定情境下表现更佳,尽管目前这种优势还不够显著。报道指出,该团队构建了一个高性能智能体,并选取超临界翼型减阻作为测试案例,展开了深入实验。据悉,这是一种基于视觉语言模型(VLM)的知识驱动型气动设计智能体框架。它通过融合气动学专业知识与历史设计数据,引导 VLM 综合理解并推理翼型几何
模速×追梦 AI 开放麦:揭秘视觉语言模型的注意力迷失
模速 × 追梦 AI网络直播视觉语言模型在注意力机制里的迷失之谜本次直播将深入探讨视觉语言模型(LVLM)面临的关键瓶颈——为何高性能模型会在注意力机制中“迷失方向”?奚工理将进行全方位解析,从注意力余诊断入手,搭建统一的解释架构,并展望多模态模型的未来演进路线。1直播亮点LVLM 的主要难点:跨模态对齐的现实困境注意力余诊断: pinpoint 模型“分心”的根源统一解释架构:重塑对注意力机制的认知未来走向:构建更高效、更具可解释性的多模态架构2直播详情受众群体:AI 科研人员、算法工程师、多模态行业专
arXiv AI论文精选 2026-05-10
1. 人机交互新基准:AI智能体何时应主动求助? 原文标题: HiL-Bench (Human-in-Loop Benchmark): Do Agents Know When to Ask for Help? 发布时间: 2026-04-10 论文链接:http://arxiv.org/abs/2604.09408v1 当前前沿编码智能体虽能在信息完备时处理复杂任务,但在面对信息残缺或语义模糊的场景时往往失效。问题根源并非能力欠缺,而是判断力的缺失:无法准确识别应独立决策还是应寻求外部支持。现有评测体系对
斯坦福3D大模型Merlin:AI读片写报告,精准预判风险
研究速览放射科医生资源短缺与CT扫描量持续攀升的矛盾愈发严峻,尤其腹部CT切片数量庞大,解读过程耗时费力。当前AI模型多局限于二维图像或简短文本,难以有效处理真实的临床三维CT数据。为此,斯坦福大学的研究团队开发了Merlin,一个专门针对腹部CT的三维视觉语言基础模型。Merlin的创新之处在于,它打破了传统“单一模态、单一任务”的局限,能够同时从海量的三维CT扫描、电子健康记录(EHR)诊断代码以及长篇放射学报告中进行联合学习。研究团队在一个A6000 GPU上,利用超过15000例CT数据完成了模型