AI评测新趋势:从榜单刷分到真实场景能力验证
过去我们更在意模型在各类排行榜上的成绩:SWE-bench、Terminal-Bench,领先几个百分点,打破纪录成为焦点。而如今,一个更核心的议题逐渐显现:这些分数,真的能反映AI在真实生产环境中的能力吗?从近期AI评测的发展来看,评测正从“短任务、单分数、排行榜”迈向“长周期、可解释、生产级、安全可信”。本周最受瞩目的项目当属 Sakana AI 推出的CoffeeBench。它不再让Agent执行几分钟就能完成的单点任务,而是搭建了一个持续90天的B2B咖啡供应链模拟平台。系统内包含6个由LLM驱动

京沪高考作文直面AI:三款大模型实战PK”,谁更胜一筹?
文|《BUG》栏目 闫妍 6月7日,2026年全国高考大幕正式拉开,千万学子奔赴考场。语文作文历来是舆论焦点,今年北京卷与上海卷的命题均紧扣科技发展与人工智能(AI)等前沿话题。 北京卷微写作设定在重阳节,学校计划组织志愿者赴敬老院开展“人工智能(AI)与幸福晚年”主题行动,要求撰写一段宣传文案,以吸引老年人积极参与。 上海卷则以70分的大作文题,抛出了一个充满哲学思辨的命题:“每个人都拥有对世界的想象。科技在重塑世界的同时,也在重塑我们的想象,对此你有何见解与思考?” 依据艾媒金榜发布的《2026年上半
SaaS-Bench评测揭示:AI办公的残酷现实与环保困境
今天想和大家分享一组令人尴尬的数据,以及一个比尴尬更值得深思的问题。2026年被业界称为"AI Agent元年"。在博鳌论坛上,各大厂商纷纷推出Computer-Use功能——听起来,AI替人类工作的美好前景似乎已经触手可及。然而就在同一天,一份评测报告彻底打破了这种乐观预期。5月25日,UniPat AI发布了SaaS-Bench评测报告。该报告选取23个真实SaaS系统、106个办公任务,对Claude、Kimi、Gemini等主流大模型进行了全面测试。测试结果令人震惊:表现最优秀的Claude Op
AI产品经理分水岭:为何评测能力决定成败
针对渴望进入AI产品经理领域的人群常犯的学习误区,本文阐述AI评测作为核心技能的重要性,厘清其与常规产品测试的本质差异,并提供入门学习的优先次序建议。技术学习优先级误区:许多 aspiring AI产品经理在入门时往往首先询问是否需要钻研算法、深究模型原理,或是掌握LangChain、Agent、RAG等术语。若缺乏AI评测知识,掌握再多技术名词也不过是纸上谈兵。正确的入门路径应优先掌握AI评测,而非盲目钻研算法公式。AI产品经理最关键的素质并非比算法工程师更精通模型,而在于能判定模型是否实用、能否上线以
AI评测工具告急:Claude Mythos横空出世,传统测试方法已不够用
你是否曾设想过,评估AI实力的工具,有朝一日会被AI本身给"弄垮"?这一天,在2026年5月8日,真实上演了。主角是Anthropic最新、也最神秘的模型——Claude Mythos。这个模型从未向公众开放,普通用户无法接触它,但它最近在AI安全评测机构METR那里创造了一个历史性的纪录:在人类需要花费16小时才能搞定的复杂编程任务上,Claude Mythos实现了50%的成功率。结果,METR的评测系统直接"瘫痪"了。METR(Machine Intelligence Evaluation & Re
AI测评神话破灭:不解题也能登顶排行榜
2026年4月,UC Berkeley研究组向科技圈投下一枚重磅炸弹。他们开发了一套自动化检测系统,对8个顶级AI Agent评测体系展开了全方位审查。结论令人震惊:全部评测体系均存在可被"劫持"的缺陷——即便不处理任何真实任务,依然能够获得近乎完美的评分。SWE-bench:100%可劫持率。WebArena:近100%。FieldWorkArena:100%。GAIA:98%。这并非纸上谈兵。研究组真实构建了可运作的漏洞利用代码,并向这些评测平台正式提交了结果。这也不是学术演练。它动摇了规模达2000
AI每日快讯 | 2026年4月10日精选
为你精选 4月10日 最值得关注的AI资讯2026年4月,一款名为HappyHorse-1.0的国产匿名视频模型在权威AI评测平台Artificial Analysis AI Video Arena排行榜上成功登顶,以更高的Elo分数力压字节跳动旗下Seedance 2.0、快手可灵AI、Google Veo 3 Fast等众多强劲对手,一举成为全球视频生成模型的新王者。据The Information报道,两位知情人士透露,HappyHorse-1.0的开发者据称是阿里巴巴集团,预计将于近期正式上线发布
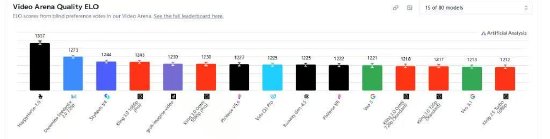
神秘AI模型HappyHorse冲上全球评测榜首,传闻出自淘天团队
新浪科技讯 4月8日晚间消息,近日有市场消息称,"近期在国际舞台备受关注的多模态大模型(开源文生视频/图生视频+音频统一大模型)HappyHorse,在多方核实后,其背后研发团队疑似来自淘天集团未来生活实验室-ATH-AI创新事业部。" 针对这一说法,新浪科技向淘天集团官方进行了求证,但截至发稿时,对方尚未作出回应。 据相关报道,在全球知名AI评测平台Artificial Analysis的Video Arena榜单中,一款代号为HappyHorse-1.0的神秘视频生成模型低调现身,并很快升至榜单第一。
Nature重磅:ADeLe精准预判AI模型成败
瓦伦西亚理工大学(Universitat Politècnica de València)的一支研究团队,来自瓦伦西亚大学人工智能研究所(VRAIN)及ValgrAI,成功研发了ADeLe。这一创新方法可精准预判大型语言模型(LLM)在未曾执行过的全新任务中的成功率,并清晰界定特定模型的推理边界。该研究刊登于《自然》期刊,堪称重大进展。传统手段仅能反映AI模型在既定测试中的成效,而ADeLe运用更具认知深度的评测方式,可预先解析并预判模型行为,使企业在发布新型AI系统前便能洞察潜在失误。如此一来,我们便能