
面壁智能推出MiniCPM5-2B端侧模型,AA-Index 4B以下性能登顶
据IT之家7月19日报道,面壁智能携手OpenBMB在2026年世界人工智能大会上发布了最新端侧模型MiniCPM5-2B,并完成了多款芯片的适配工作。 官方透露,在最新一期Artificial Analysis(AA)榜单评测中,MiniCPM5-2B以17分的成绩夺得榜首,成为全球4B以下模型中得分最高的产品。 据介绍,MiniCPM5-2B模型原生支持混合推理模式,能够在快速响应与深度思考间灵活切换,并具备512K超长上下文窗口,可一次性处理整本长篇小说或数十万行代码。其能力覆盖通用知识、数学与代码
AI今日焦点:系统可靠性成新战场
AI今日焦点DAILY AI BRIEF · VERIFIED TODAY ONLYTODAY'S DATE2026.07.19America/Los_Angeles 截稿 07:57 PDT日期审计:仅纳入 2026.07.19 00:00—07:57(PDT)新增报道、当日日程或当日社区帖子;没有用更早内容补位。开放权重、长上下文与物理智能 成为今天的三条主线截至西海岸早晨,今天可核验的新信号并不密集,却高度集中:Kimi K3 引发美国政策与安全人物的公开反应;黄仁勋的“物理 AI”路线成为机器人产
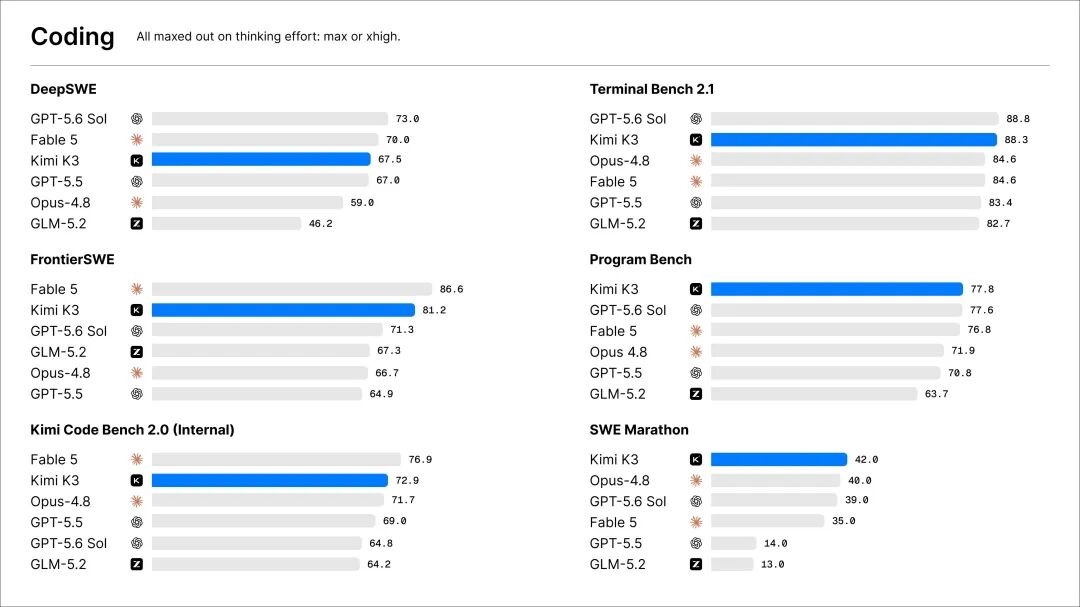
2.8万亿参数!全球最强开源模型Kimi K3正式发布
7月17日凌晨,月之暗面正式对外公布,推出公司迄今能力最强的大模型Kimi K3。 根据披露信息,K3是一款拥有2.8万亿参数的模型,具备100万token的上下文窗口,是目前全球参数量最大的开源模型,也是首个突破2万亿级别的模型,专为软件工程、知识处理及深度推理等前沿智能场景打造。 在官方评测中,Kimi K3展现了领先的表现。在参与测试的所有模型中,其综合智能水平仅次于Claude Fable 5和GPT-5.6 Sol。 7月17日凌晨,外界期待已久的Kimi新一代模型终于揭开面纱。 官方信息显示,
AI Infra 核心竞争力何在?| 直播预告
随着模型能力的不断突破,AI基础设施的竞争格局正在被重塑。7月8日晚8点,来自vLLM、范式智能以及华为的技术大咖齐聚一堂,深入剖析推理工程的最新进展,共同展望AI基础设施的未来走向。7 月 8 日 20:00-21:30AI编程如此强大,为何企业开发效率仍未提升?主持人 & 嘉宾:黄之鹏,华为 AI 开源生态总监嘉宾:莫梓峰,Inferact vLLM committer杨守仁,范式智能(第四范式)系统研发专家聚焦 AI Infra 最前沿,开源项目一线核心贡献者同台对话拆解推理工程核心挑战,聊
4月AI模型进展盘点
📰 模型支持 2M token 的长上下文能力,采用 Symphony 架构(原生多模态 + 双系统推理)整体性能提升约 40%,Altman 将其称为"AGI 最后一公里"推出 V4-Pro(1.6T 参数)与 V4-Flash(284B 参数)两条路线将 1M token 上下文设为默认配置,1M token 的价格约为 1 元Ultra-MoE 架构:总参数规模达 1T,实际激活区间为 130-370B关键在于全面适配华为昇腾,真正摆脱英伟达 CUDA 依赖通过群体记忆蒸馏,将 8
GPT-5.5全量开放:AI不再“胡说”
📅 2026年5月6日5月5日,OpenAI正式推出GPT-5.5双模型(Ultra+Instant),并在今天面向全球进行全量开放,带来AI能力的又一次明显跃升!此次升级的亮点主要有三方面:幻觉问题大幅降低,下降幅度达到52.5%;在医疗、金融、法律等高风险场景中,答复更为干净利落,真正走出"AI胡说"带来的困扰;同时推理、编程与数学能力对GPT-4实现全面超越,支持百万字级长上下文,可一键拆解整本书与全量代码库;另外响应速度也显著加快,提升40%,复杂任务能够一次性给出结果。52.5%
DeepSeek驱动的AI编程新路数:高性价比代码助手全指南
在 AI 编程智能体(Agentic Coding Assistant)从基础代码补全走向“数字同事”的浪潮里,Anthropic 的 Claude Code 早已成为标杆。它不只是理解上下文,更能独立执行 Bash 命令、操纵文件系统,并保留长期记忆能力。不过对中国开发者以及那些把 ROI 视为核心考量的技术团队来说,官方路线正逐渐暴露出明显的战略卡点:不是能力不够,而是落地成本与效率之间的矛盾。本文并非单纯把某个工具当成替代品来介绍,而是一份面向中国开发者生态的“技术突围思路”。通过引入 DeepSe
智能医疗前沿速递 | 2026.05.04
## 🔥 热点聚焦[NVIDIA Nemotron 3 Nano Omni亮相:赋能文档音视频代理的长文本多模态技术]1.NVIDIA推出Nemotron 3 Nano Omni多模态系统,融合文本、图像、视频与音频的联合解析;2.该模型在MMlongbench-Doc、OCRBenchV2、WorldSense等评测中斩获顶尖成绩;3.系统搭载Nemotron 3混合Mamba-Transformer专家架构,集成C-RADIOv4-H视觉编码器及Parakeet-TDT-0.6B-v2音频编码器。([
极AI前沿周报速览
本期周报对 2026 年 04 月 22 日至 04 月 29 日期间 AI 领域的关键变化进行梳理,重点覆盖基础技术的突破、产品与商业层面的动向、跨行业融合的趋势,同时追踪人才与观点,提炼出值得关注的核心信号及其潜在战略含义。以下内容由北京中关村学院信息智能系统自动汇总生成,仅供参考。01.极基础底层范式与方法论演变本周总结本周多项发布释放出一致信号:AI 智能体正在从展示能力走向真正的业务执行落地,模型能力、推理的成本效率以及底层算力都在围绕“可用与可做”同步升级。能力层面——Kimi K2.6 与
AI晨报|4月29日产业快讯
聚焦「Bug与灵光」,为你持续追踪AI产业最新进展① OpenAI Codex 落地亚马逊 Bedrock,微软独家绑定告终 4月29日,OpenAI宣布 Codex 编程助手正式接入 AWS 平台:开发者可以直接在 Amazon Bedrock 中调用其最新模型,并完成 AI Agent 的部署。这也意味着在OpenAI与微软解除独家云合作之后,出现的首个可见落地案例,预示OpenAI将加速推进多云布局。② 微软与 OpenAI 解约:7年独家合作终结 4月27日,微软与 OpenAI 公布对合作协议的
AI前沿动态:OpenAI策略调整,大模型与智能体技术并行发展
• OpenAI与微软的合作关系迎来重大调整,OpenAI现在可在微软之外的云平台提供服务,并已确认模型即将登陆AWS Bedrock,标志着其分发策略的扩展。此次调整也意味着微软对OpenAI IP的独家授权终止。• GPT-5.5模型正式推出,在多项社区评测中展现出显著性能提升,尤其在某些高难度编码任务上表现突出,但在综合性评测中并非全面领先。值得关注的是,GitHub Copilot将转向基于使用量的计费模式,Codex模型的经济模型也愈发清晰,预示着AI开发成本管理的重要性日益提升。• 中国大模型
DeepSeek开源爆火:开发者不再看OpenAI脸色
开源AI这半年,热度一直没断。大家都看得很清楚:AI圈的节奏,过去常被GPT、Claude、Gemini这些海外巨头牵着走,只要他们一发布新模型,媒体和技术圈就会立刻起波澜。但说到底,真正决定“能不能落地”的,往往不是最会讲故事的厂商,而是更接地气的开源社区。道理就是这么简单。DeepSeek一次性放出了V4-Pro和V4-Flash两个版本。可大家更爱看的,还是它们的跑分和参数规模,真正关心它能不能在生产环境里稳定运行的人并不多。媒体爱热闹,发烧友爱刷榜,极客爱比数字,但很少有人真把它深度接进业务,更少

DeepSeek再降价
界面新闻记者 | 宋佳楠 DeepSeek正不断重塑大模型普惠的边界。 4月26日,DeepSeek官方公布API调价公告,全系API输入缓存命中价格降至首发时的十分之一,V4-Pro再叠加限时2.5折,百万Tokens输入缓存命中最低仅0.025元,刷新全球大模型价格纪录。 按DeepSeek官方API定价页显示,此次降价覆盖V4系列全部模型,重点调整集中在输入缓存命中场景。其中DeepSeek-V4-Flash的输入缓存命中价格由0.2元/百万Tokens降至0.02元/百万Tokens。 面向企业级
DeepSeek-V4成龙虾默认模型
全球Agent(智能体)风向标OpenClaw正式宣布接入DeepSeek-V4。 4月26日,澎湃新闻记者获悉,OpenClaw(龙虾)已正式官宣,全面接入DeepSeek-V4(Flash和Pro双版本),其中V4 Flash成为默认大模型,V4 Pro也同步上架模型库。 据OpenClaw披露,最新的4.24版本更新包含:实时语音通话全面贯通;DeepSeek-V4-Flash和Pro加入模型库;浏览器自动化新增坐标点击和更完善的恢复机制;Telegram、Slack、MCP、会话以及TTS均已修复

阿里云百炼平台首发DeepSeek-V4,API定价与官网同步
IT之家4月24日讯,阿里云百炼平台正式推出DeepSeek-V4-Pro及DeepSeek-V4-Flash两款模型,其接口费用与DeepSeek官方保持完全一致,其中Flash版本每百万Token输入最低仅需1元,输出最低2元。阿里云百炼平台是集成模型调用、参数调优、知识库构建等功能的综合性AI研发平台。此次引入DeepSeek-V4系列,再度扩充了其AI模型库资源,助力开发者在统一平台便捷调用各类顶尖模型。本次发布的核心亮点是DeepSeek-V4系列双模型布局:针对高难度任务打造的Pro版本,以及